This is a case study where I walk you through my thought process as I optimize one of my old shaders to run 5x faster.
During my studies, while traveling on the train, I used to prototype shaders. Usually, I had an idea for an effect, 3 hours of travel, and no internet. This pushed my creativity.
And during this time, I created this shader on Shadertoy: https://www.shadertoy.com/view/ttSGz3.
Now that I have a better understanding of GPU optimizations, I want to push my limits and see how much I can optimize this shader. The shader is code-only and doesn't use any textures, so my first idea is to utilize texturing units, which can run in parallel to math instructions.
To do that, I will quickly port it into HLSL and import it into Unity, so I can work with my favorite GPU profiler: Nvidia Nsight Graphics. I asked ChatGPT to do everything for me, and it had the shader running in Unity in no time. This is the ported shader file I started with in Unity: https://gitlab.com/-/snippets/4906196.
Please ignore the code quality and variable naming; it was a long time ago, and I was just having fun and didn't care.
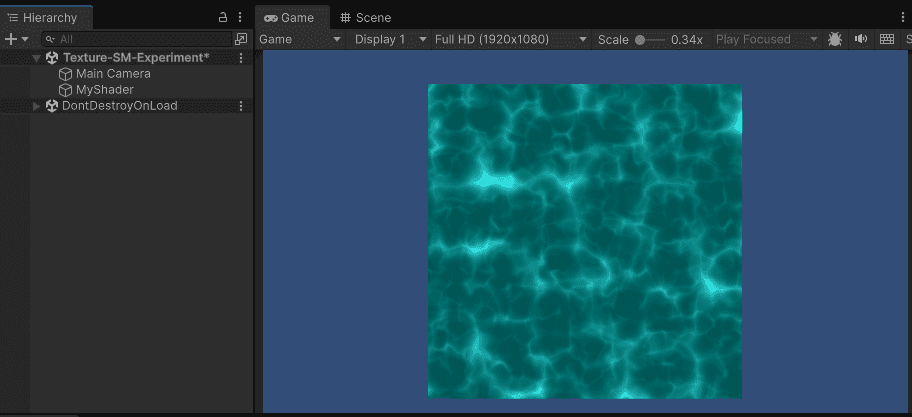
If you want, you can experiment on your own before reading further.
___
How the shader works
Before I go into the optimization loop, I feel obligated to explain how the shader works. If you don't care about this, feel free to skip this section and get straight to the main part.
So...
It works by combining four animated cellular noise layers. To sample those layers, I used a distorted UV, which is distorted by value noise.
All the textures here are procedural, meaning they are functions in the shader code, not texture assets.
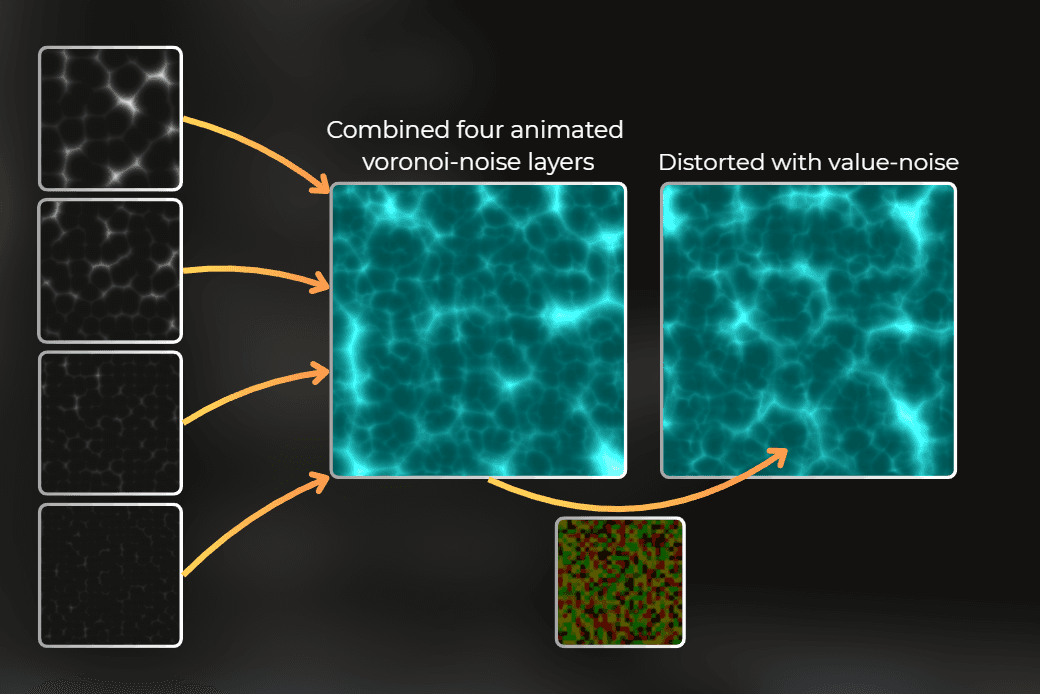
___
Cellular noise
This is a code that samples a cellular noise (Voronoi noise). I added some comments so it is easier to understand. If you want to understand how it works, I could recommend this tutorial: "The Book of Shaders - Cellular Noise".
float2 Hash2_2(float2 x)
{
float2 v = sin(mul(x, float2x2(20.52, 24.1994, 70.291, 80.171))) * 492.194;
return frac(v);
}
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (Hash2_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5;
}
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDist = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * Hash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float dist = length(uv - p);
if (dist < minDist)
minDist = dist;
}
}
return minDist
float2 Hash2_2(float2 x)
{
float2 v = sin(mul(x, float2x2(20.52, 24.1994, 70.291, 80.171))) * 492.194;
return frac(v);
}
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (Hash2_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5;
}
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDist = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * Hash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float dist = length(uv - p);
if (dist < minDist)
minDist = dist;
}
}
return minDist
float2 Hash2_2(float2 x)
{
float2 v = sin(mul(x, float2x2(20.52, 24.1994, 70.291, 80.171))) * 492.194;
return frac(v);
}
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (Hash2_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5;
}
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDist = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * Hash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float dist = length(uv - p);
if (dist < minDist)
minDist = dist;
}
}
return minDist
Cellular noise works by scanning the 3x3 window and calculating the distance to the closest cell center.
:center-50:
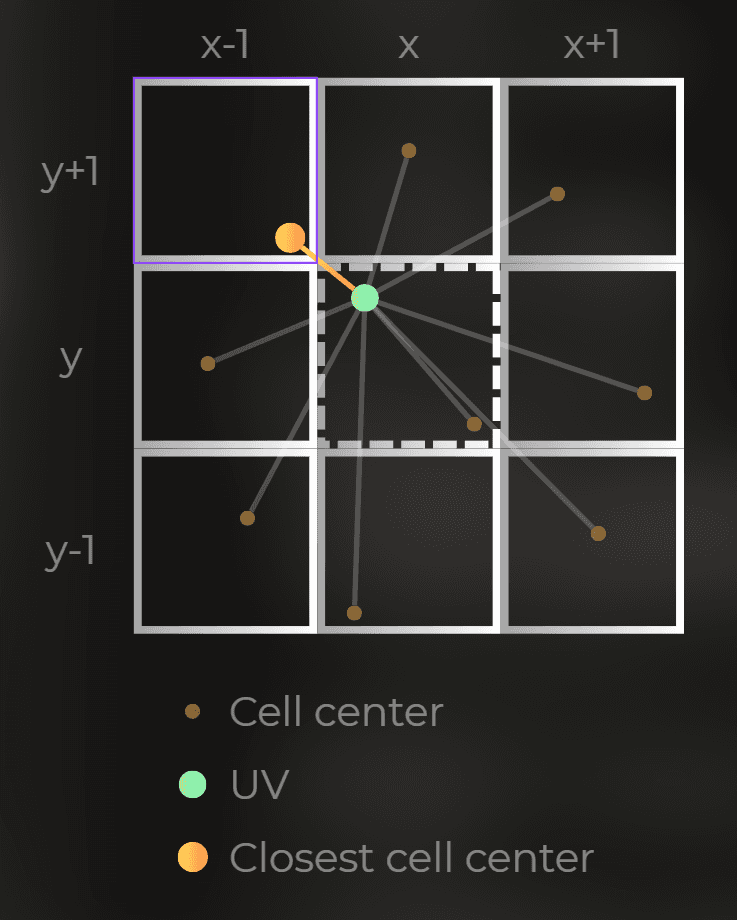
And the above Voronoi function draws something like this:
___
Combining four layers of cellular noise
Then, I combine the four layers of this noise using this method:
float FractVoronoi(float2 uv, float sizeMul, float alphaMul, int layers)
{
float noise = 0.0;
float size = 1.0;
float alpha = 1.0;
for (int i = 0; i < layers; i++)
{
float2 offs = (((i + 1.0) / layers)) * 0.5 * _Time.y * WATER_SPEED;
noise += pow(Voronoi((uv + offs) * size) * alpha + Voronoi_BRIGHTNESS_ADD, Voronoi_NOISE_POW);
size *= sizeMul;
alpha *= alphaMul;
}
noise *= (1.0 - alphaMul) / (1.0 - pow(alphaMul, layers));
return noise
float FractVoronoi(float2 uv, float sizeMul, float alphaMul, int layers)
{
float noise = 0.0;
float size = 1.0;
float alpha = 1.0;
for (int i = 0; i < layers; i++)
{
float2 offs = (((i + 1.0) / layers)) * 0.5 * _Time.y * WATER_SPEED;
noise += pow(Voronoi((uv + offs) * size) * alpha + Voronoi_BRIGHTNESS_ADD, Voronoi_NOISE_POW);
size *= sizeMul;
alpha *= alphaMul;
}
noise *= (1.0 - alphaMul) / (1.0 - pow(alphaMul, layers));
return noise
float FractVoronoi(float2 uv, float sizeMul, float alphaMul, int layers)
{
float noise = 0.0;
float size = 1.0;
float alpha = 1.0;
for (int i = 0; i < layers; i++)
{
float2 offs = (((i + 1.0) / layers)) * 0.5 * _Time.y * WATER_SPEED;
noise += pow(Voronoi((uv + offs) * size) * alpha + Voronoi_BRIGHTNESS_ADD, Voronoi_NOISE_POW);
size *= sizeMul;
alpha *= alphaMul;
}
noise *= (1.0 - alphaMul) / (1.0 - pow(alphaMul, layers));
return noise
And it produces this image:
Distorting the UV
To make it feel more water-like, the UV to sample the layers is distorted using a smoothed value noise.
float2 Noise2_2(float2 uv)
{
float2 f = smoothstep(0.0, 1.0, frac(uv));
float2 uv00 = floor(uv);
float2 uv01 = uv00 + float2(0,1);
float2 uv10 = uv00 + float2(1,0);
float2 uv11 = uv00 + 1.0;
float2 v00 = Hash2_2(uv00);
float2 v01 = Hash2_2(uv01);
float2 v10 = Hash2_2(uv10);
float2 v11 = Hash2_2(uv11);
float2 v0 = lerp(v00, v01, f.y);
float2 v1 = lerp(v10, v11, f.y);
return lerp(v0, v1, f.x
float2 Noise2_2(float2 uv)
{
float2 f = smoothstep(0.0, 1.0, frac(uv));
float2 uv00 = floor(uv);
float2 uv01 = uv00 + float2(0,1);
float2 uv10 = uv00 + float2(1,0);
float2 uv11 = uv00 + 1.0;
float2 v00 = Hash2_2(uv00);
float2 v01 = Hash2_2(uv01);
float2 v10 = Hash2_2(uv10);
float2 v11 = Hash2_2(uv11);
float2 v0 = lerp(v00, v01, f.y);
float2 v1 = lerp(v10, v11, f.y);
return lerp(v0, v1, f.x
float2 Noise2_2(float2 uv)
{
float2 f = smoothstep(0.0, 1.0, frac(uv));
float2 uv00 = floor(uv);
float2 uv01 = uv00 + float2(0,1);
float2 uv10 = uv00 + float2(1,0);
float2 uv11 = uv00 + 1.0;
float2 v00 = Hash2_2(uv00);
float2 v01 = Hash2_2(uv01);
float2 v10 = Hash2_2(uv10);
float2 v11 = Hash2_2(uv11);
float2 v0 = lerp(v00, v01, f.y);
float2 v1 = lerp(v10, v11, f.y);
return lerp(v0, v1, f.x
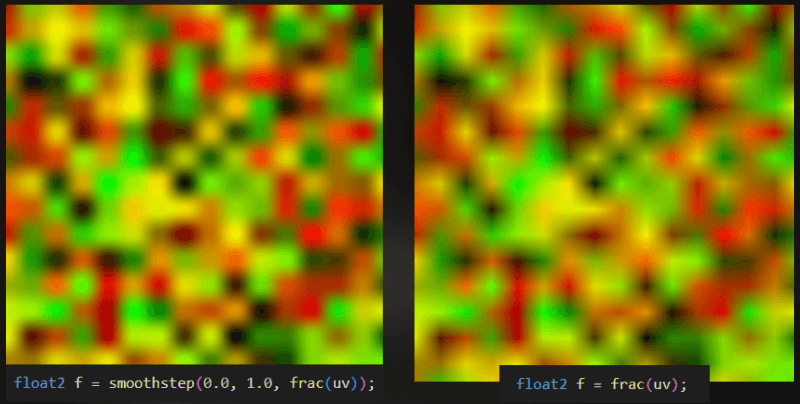
This is the noise. I used the version on the left, with non-linear interpolation.
And this is how a distorted layers look:
float2 n2 = Noise2_2(uv * UV_DISPLACEMENT_SIZE) * UV_DISPLACEMENT_STRENGTH;
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS);
float2 n2 = Noise2_2(uv * UV_DISPLACEMENT_SIZE) * UV_DISPLACEMENT_STRENGTH;
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS);
float2 n2 = Noise2_2(uv * UV_DISPLACEMENT_SIZE) * UV_DISPLACEMENT_STRENGTH;
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS);
___
Postprocess
The process is simple color grading, making black blue and white white-blue.
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS);
float res = smoothstep(-0.2, 0.3, fV);
return float4(res.xxx, 1.0) * WATER_COLOR + fV
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS);
float res = smoothstep(-0.2, 0.3, fV);
return float4(res.xxx, 1.0) * WATER_COLOR + fV
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS);
float res = smoothstep(-0.2, 0.3, fV);
return float4(res.xxx, 1.0) * WATER_COLOR + fV
And this is the final effect:
___
Optimization routine
To optimize the shader, I will use Nvidia Nsight Graphics 2025.4.1 and profile the workload on RTX 3060.
I will build this scene so the quad with the shader takes up most of the screen, and profile it in full-screen 2560x1400. In this scenario, I can focus solely on shader bottlenecks without worrying about triangle distribution, density, color blending, or depth throughput.
My goal is to profile the shader in Nvidia Nsight Graphics, introduce another change based on what I see in the profiler, and then profile again. I will do this as long as I can make the shader run faster.

___
Understanding the GPU profiling data
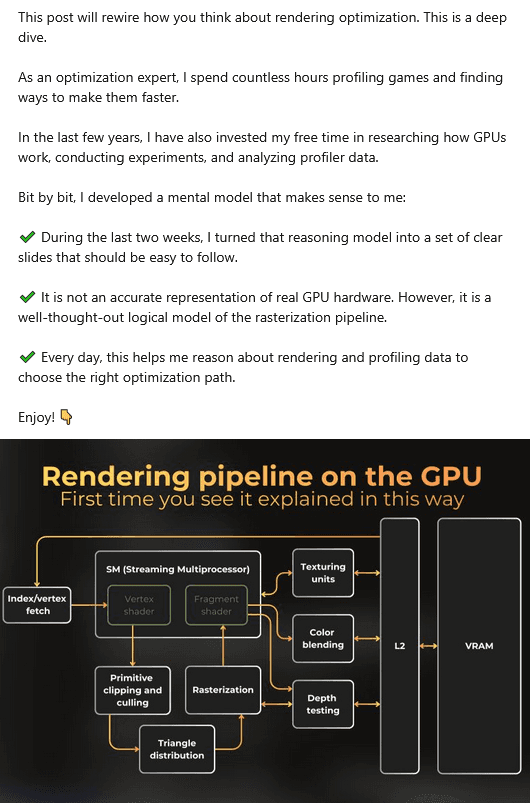
First of all, it is important to understand how to interpret the profiler data to reach correct conclusions when optimizing the shader. I will profile the shader in a near-fullscreen quad, so the real bottleneck will be the shader itself. Shaders are executed by SM units on Nvidia GPUs, so it is important to understand how the units are organized and how shader execution occurs.
___
Mental model of the shader execution unit
On Ampere, Nvidia launches shaders in warps, with each warp using up to 32 threads. However, the single-thread group contains a few execution pipes that can run concurrently. Each pipe is designed for a specific instruction.
This is my mental model of the SM unit in the Ampere architecture.
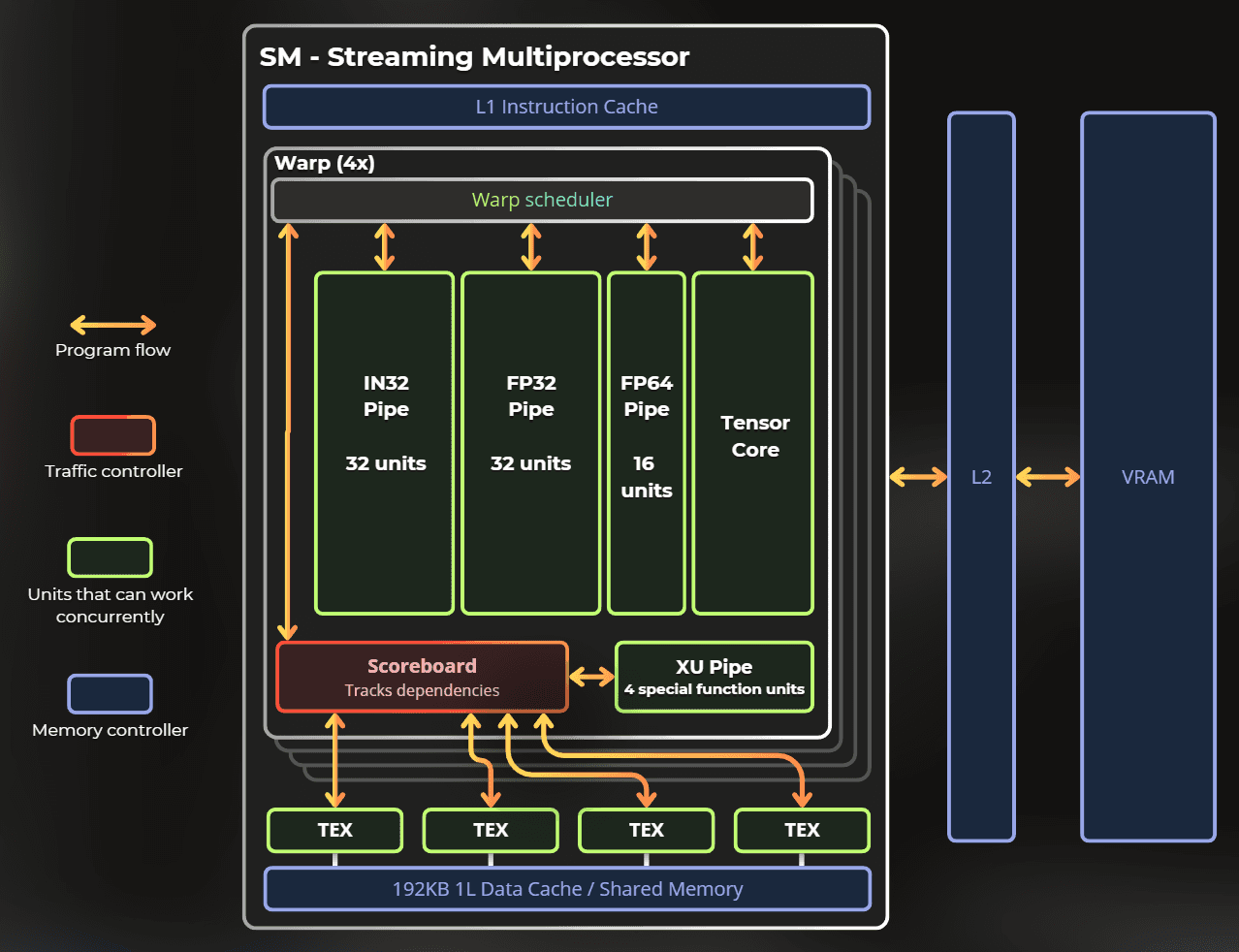
Notice that it contains a few pipes. Those pipes can execute instructions simultaneously. A shader that uses only FP32 math will run slower than one that utilizes INT32, FP32, special functions, and textures to achieve the same result.
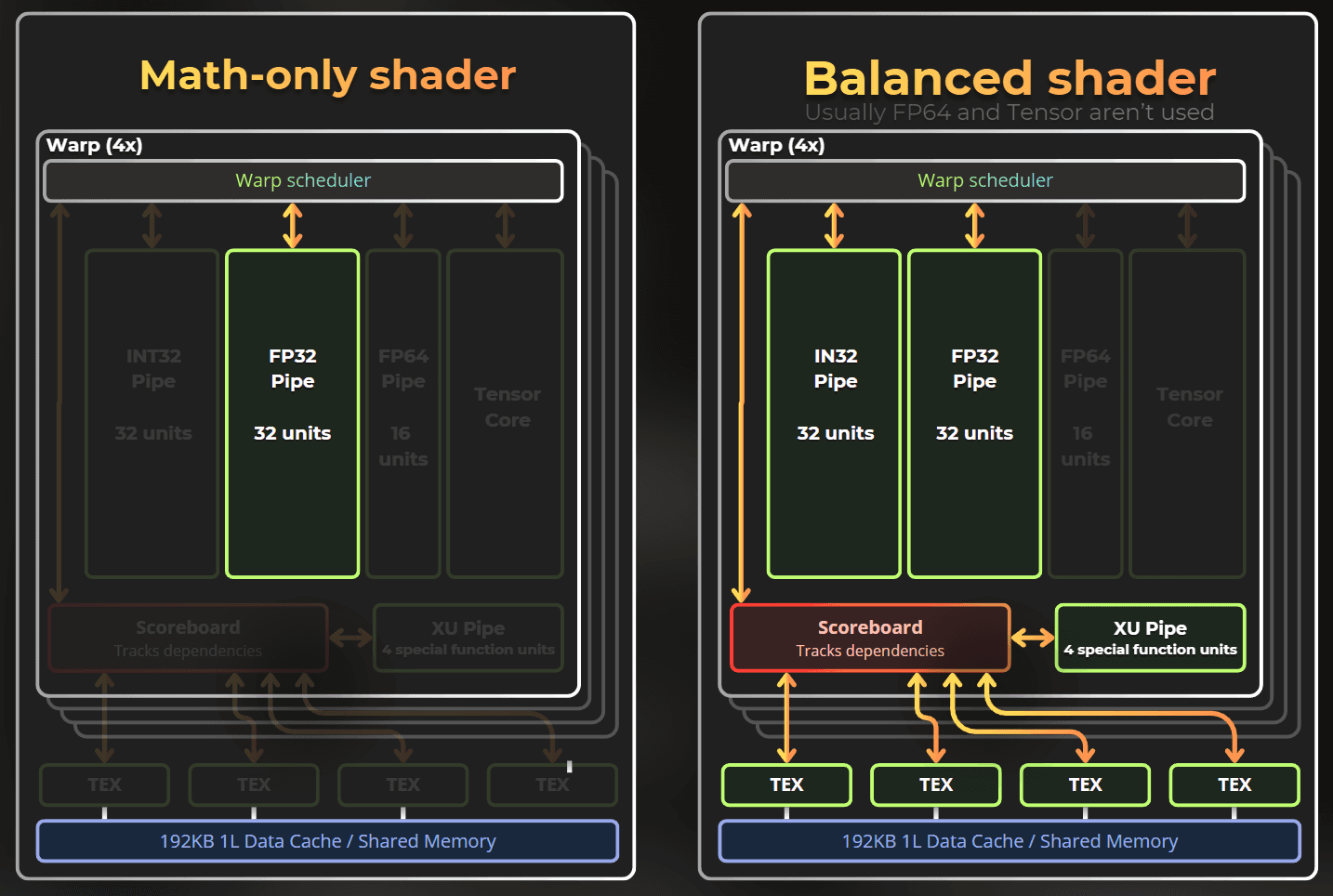
In the balanced shader, the ALU, FP32, XU, and texturing units can run concurrently, increasing the overall efficiency of the SM unit.
Note: This mental model may not be true for other GPU architectures. Across all architectures, texturing units and shader execution units are separate and run in parallel.
I will profile and optimize the shader in the context of the model described above and show you that it works.
___
Initial shader profiling
So I profiled the original shader using Nvidia's GPU Trace.
It is a bit overwhelming at first, so I will explain what I am looking for when browsing a profile.
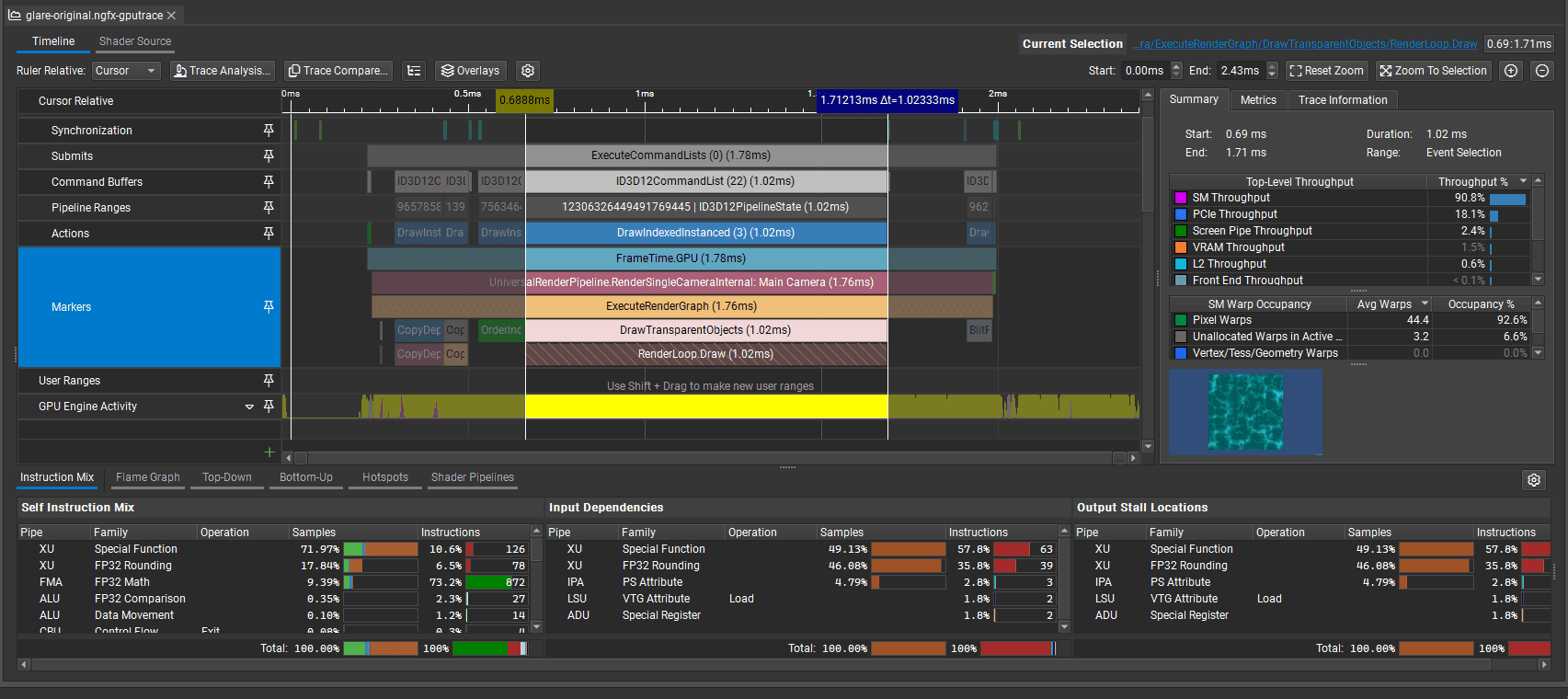
At first, I find the specific draw call that used this shader and look at it's summary. It shows which GPU units were used the most. Those are usually a bottleneck of this draw call.
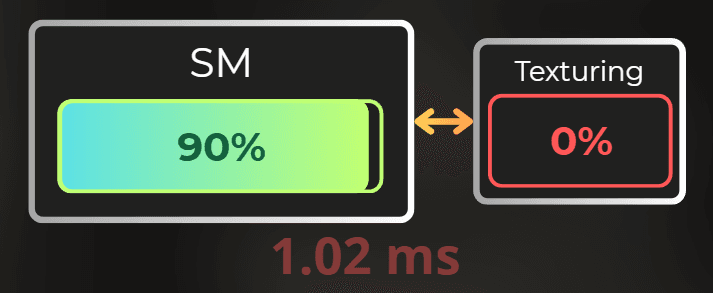
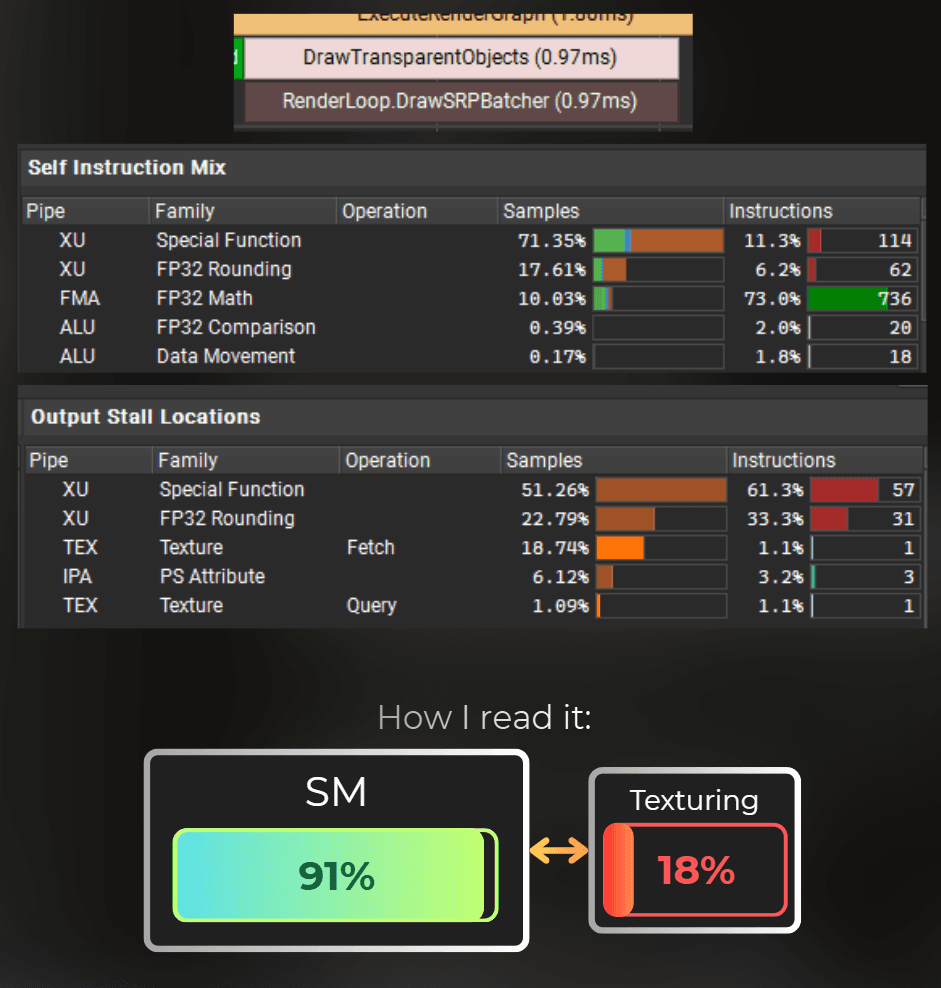
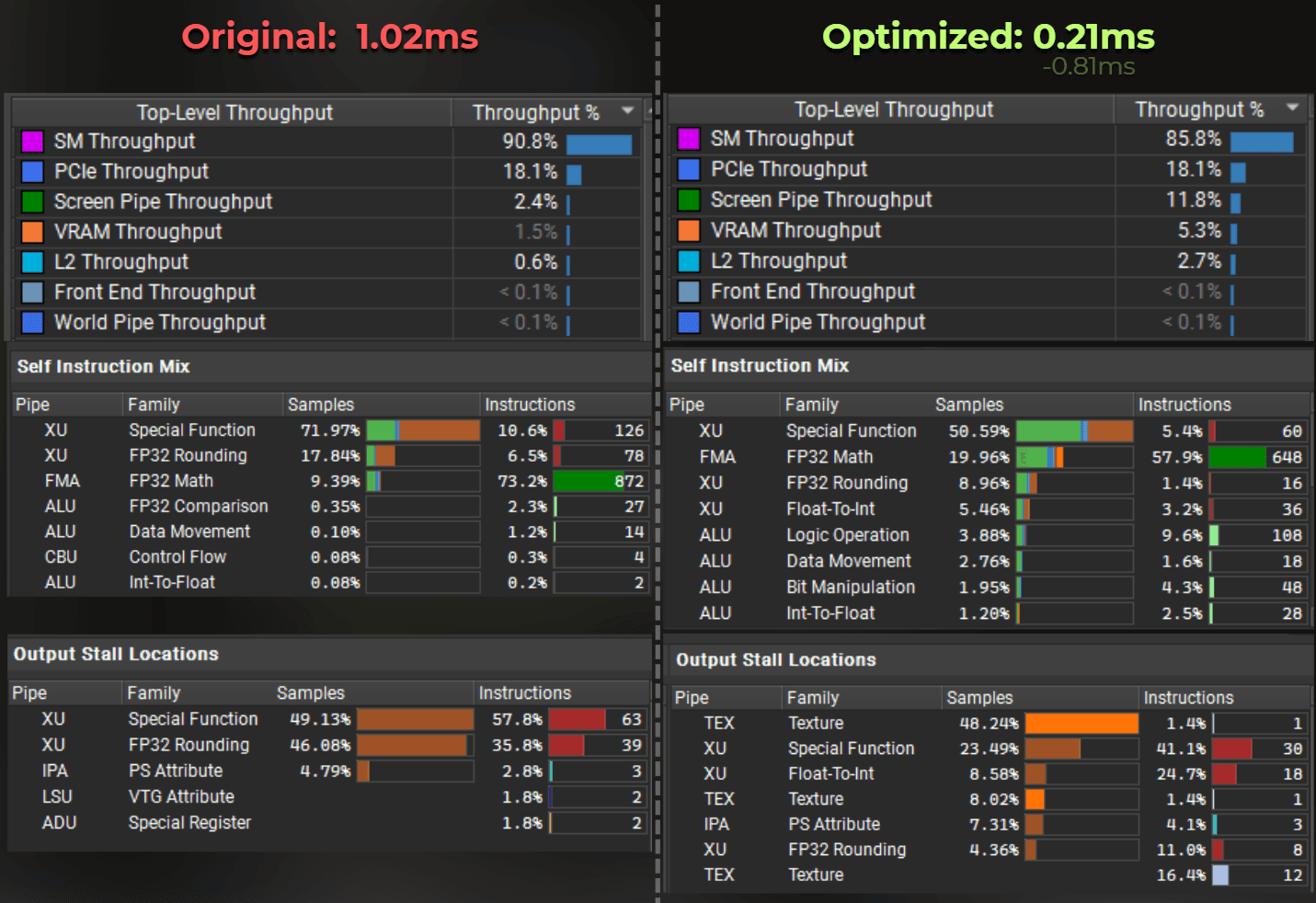
In this case, SM units kept working at 90.8% of their throughput, indicating they are the main bottleneck, so I have a correct setup for shader optimization.
From the screenshot below, I can see that 92% of the SM occupancy was spent executing the fragment shader.
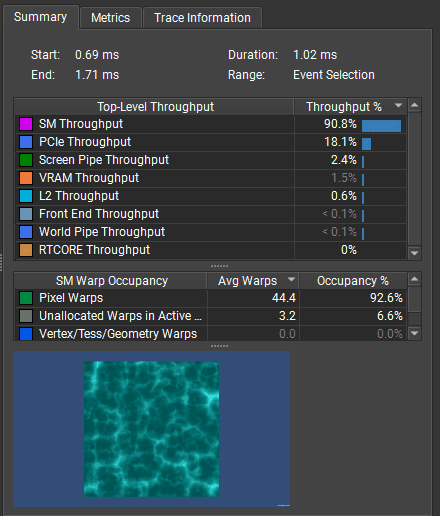
If the draw call is shader-bound - like in this case, I dive into the shader instruction mix and stalls.
From the instruction mix I can see that most of the shader's time was spent on special functions (like sin, cos, sqrt, rounding) and simple math operations (FP32 Math).
The green part of the bar represents how much time the GPU spent executing this instruction. The orange part indicates that it was waiting for this instruction to complete but stalled for some reason (e.g., waiting for other units).
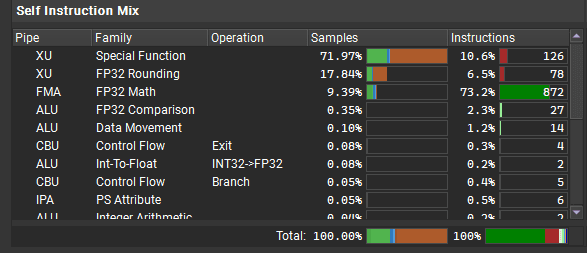
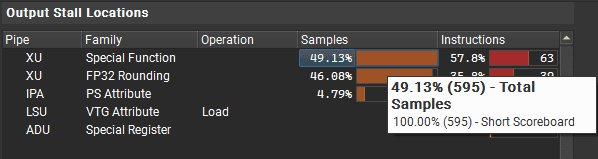
Then, from the Output Stall Locations, I can see what the shader was waiting for on those instructions. I can see that for Special Function and FP32 Rounding the GPU must've waited for Short Scoreboard. In this architecture, the scoreboard is a section of the SM unit that delegates work to the other units.
To execute a special function, the shader program writes a new entry to the scoreboard (a communication interface between various SM internal units). Then the SFU (special function unit) reads the scoreboard, executes the operation, and writes the result back to the scoreboard.
To illustrate it simply. The current shader uses many specialized functions, which are slow because there are fewer GPU units capable of handling them. Moreover, no textures are used, leaving the texturing units idle.
Or a more advanced representation of the current shader's work:
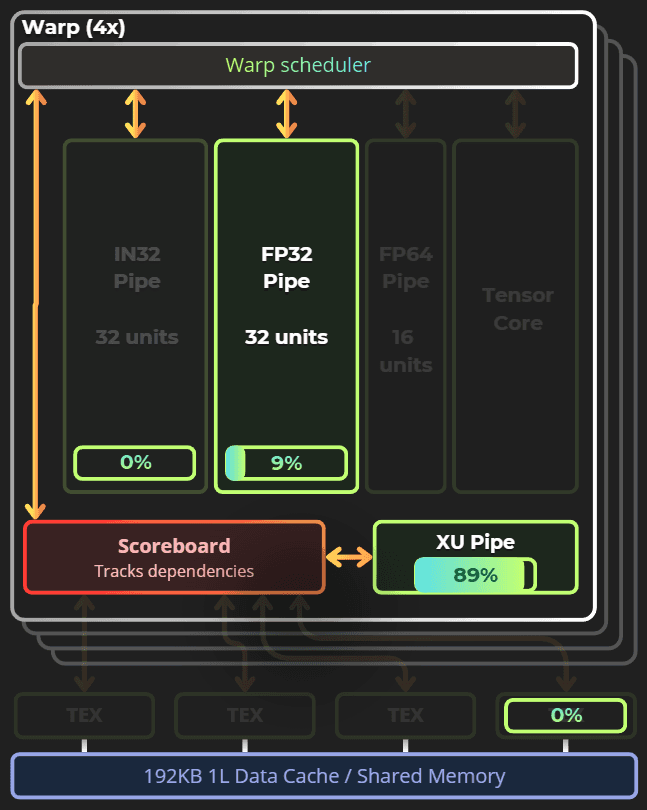
The shader code relies mostly on Special Functions, which are much slower than FP32. It also doesn't use any texturing units or INT32 units.
So I can optimize this shader by moving some of the special functions into FP32, INT32, or TEX workload.
It will look like moving sin/cos/rounding, etc., into texture lookups or replacing them with integer calculations.
___
Optimization iterations
Now that I understand the bottlenecks, I'll iteratively optimize the shader, profiling after each change to measure the impact.
___
Optimizing the noise distortion
The shader uses procedural noise to distort the final result. I will start by optimizing this noise and replacing it with a texture lookup. This is a fragment of the shader code.
float2 n2 = Noise2_2(uv * UV_DISPLACEMENT_SIZE) * UV_DISPLACEMENT_STRENGTH;
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS
float2 n2 = Noise2_2(uv * UV_DISPLACEMENT_SIZE) * UV_DISPLACEMENT_STRENGTH;
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS
float2 n2 = Noise2_2(uv * UV_DISPLACEMENT_SIZE) * UV_DISPLACEMENT_STRENGTH;
float fV = FractVoronoi(uv + n2, SIZE_MUL, ALPHA_MUL, LAYERS
I will replace it with one texture read. I used GIMP and the value noise filter to generate a 64x64 texture. Uncompressed texture of this size with 32-bit/pixel has only 16KB. According to the Ampere architecture whitepaper, this texture will fit entirely in L1 cache, ensuring that texturing units achieve a 100% hit rate when accessing it.

Then I used this texture instead of the procedural noise. This is how the modified code looks.
float2 smoothedUV = uv * UV_DISPLACEMENT_SIZE - 0.5;
smoothedUV = floor(smoothedUV) + smoothstep(0.0, 1.0, (smoothedUV - floor(smoothedUV))) + 0.5;
float2 noiseResolution;
_NoiseRGBA.GetDimensions(noiseResolution.x, noiseResolution.y);
float2 n2 = (_NoiseRGBA.Sample(linearRepeatSampler, smoothedUV / noiseResolution).rg) * UV_DISPLACEMENT_STRENGTH
float2 smoothedUV = uv * UV_DISPLACEMENT_SIZE - 0.5;
smoothedUV = floor(smoothedUV) + smoothstep(0.0, 1.0, (smoothedUV - floor(smoothedUV))) + 0.5;
float2 noiseResolution;
_NoiseRGBA.GetDimensions(noiseResolution.x, noiseResolution.y);
float2 n2 = (_NoiseRGBA.Sample(linearRepeatSampler, smoothedUV / noiseResolution).rg) * UV_DISPLACEMENT_STRENGTH
float2 smoothedUV = uv * UV_DISPLACEMENT_SIZE - 0.5;
smoothedUV = floor(smoothedUV) + smoothstep(0.0, 1.0, (smoothedUV - floor(smoothedUV))) + 0.5;
float2 noiseResolution;
_NoiseRGBA.GetDimensions(noiseResolution.x, noiseResolution.y);
float2 n2 = (_NoiseRGBA.Sample(linearRepeatSampler, smoothedUV / noiseResolution).rg) * UV_DISPLACEMENT_STRENGTH
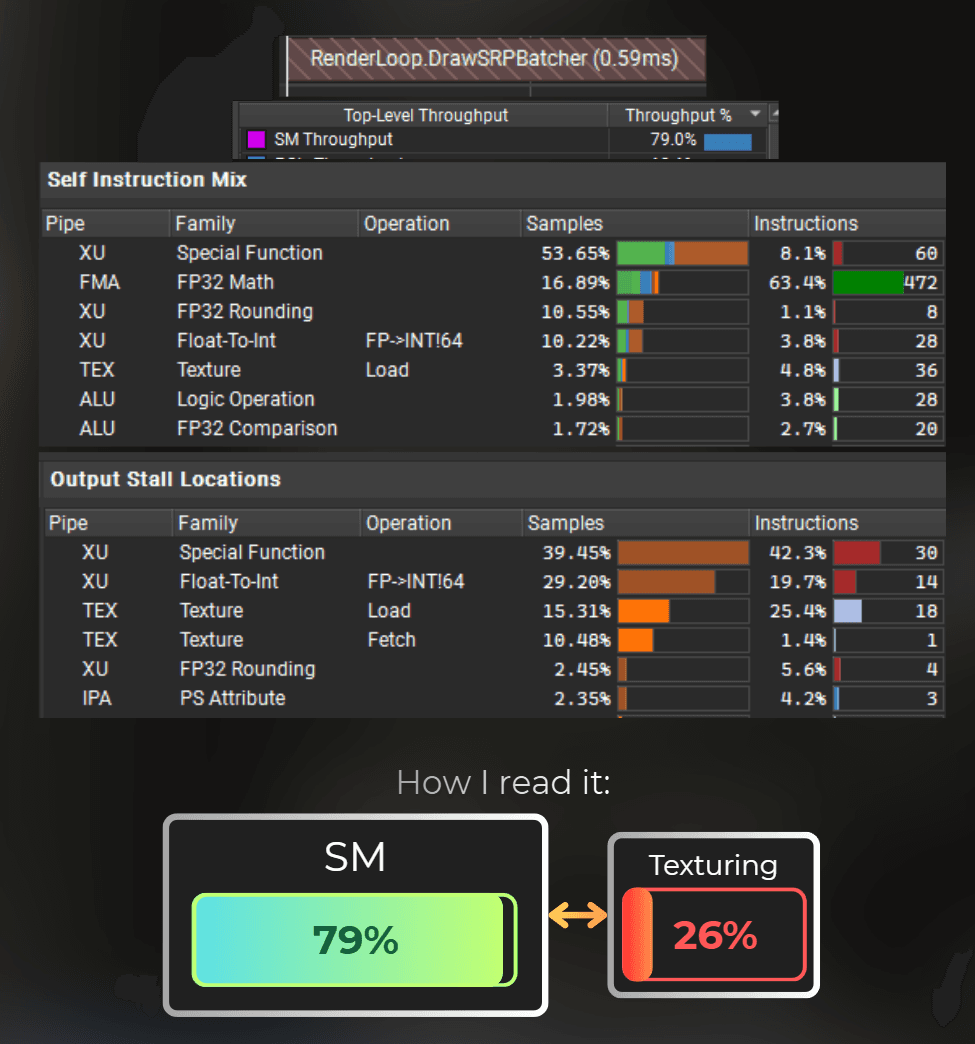
And those are the profiling results. I can see some texture units showing up, the shader runs ~0.05ms faster.
___
Optimizing the hash functions
Voronoi noise uses hash functions to randomize the cells. My idea is to shift the hash functions from being special-function-dependent to look-up-texture.
So those are the current hash functions. They use frac and sin, which are slow, special functions. It means they are executed by the less efficient XU pipe. By moving it to anything else, they should run faster.
float Hash1_2(float2 x)
{
return frac(sin(dot(x, float2(52.127, 61.2871))) * 521.582);
}
float2 Hash2_2(float2 x)
{
float2 v = sin(mul(x, float2x2(20.52, 24.1994, 70.291, 80.171))) * 492.194;
return frac(v
float Hash1_2(float2 x)
{
return frac(sin(dot(x, float2(52.127, 61.2871))) * 521.582);
}
float2 Hash2_2(float2 x)
{
float2 v = sin(mul(x, float2x2(20.52, 24.1994, 70.291, 80.171))) * 492.194;
return frac(v
float Hash1_2(float2 x)
{
return frac(sin(dot(x, float2(52.127, 61.2871))) * 521.582);
}
float2 Hash2_2(float2 x)
{
float2 v = sin(mul(x, float2x2(20.52, 24.1994, 70.291, 80.171))) * 492.194;
return frac(v
I decided to use the same 64x64 noise texture as a LUT (lookup table) for hash functions and replaced all instances in the code with the TextureHash functions instead.
float2 TextureHash2_2(float2 uv)
{
return _NoiseRGBA.Load(uint3((uint2)floor(uv + 41) % 64, 0)).br;
}
float TextureHash1_2(float2 uv)
{
return (_NoiseRGBA.Load(uint3((uint2)floor(uv) % 64, 0)).g
float2 TextureHash2_2(float2 uv)
{
return _NoiseRGBA.Load(uint3((uint2)floor(uv + 41) % 64, 0)).br;
}
float TextureHash1_2(float2 uv)
{
return (_NoiseRGBA.Load(uint3((uint2)floor(uv) % 64, 0)).g
float2 TextureHash2_2(float2 uv)
{
return _NoiseRGBA.Load(uint3((uint2)floor(uv + 41) % 64, 0)).br;
}
float TextureHash1_2(float2 uv)
{
return (_NoiseRGBA.Load(uint3((uint2)floor(uv) % 64, 0)).g
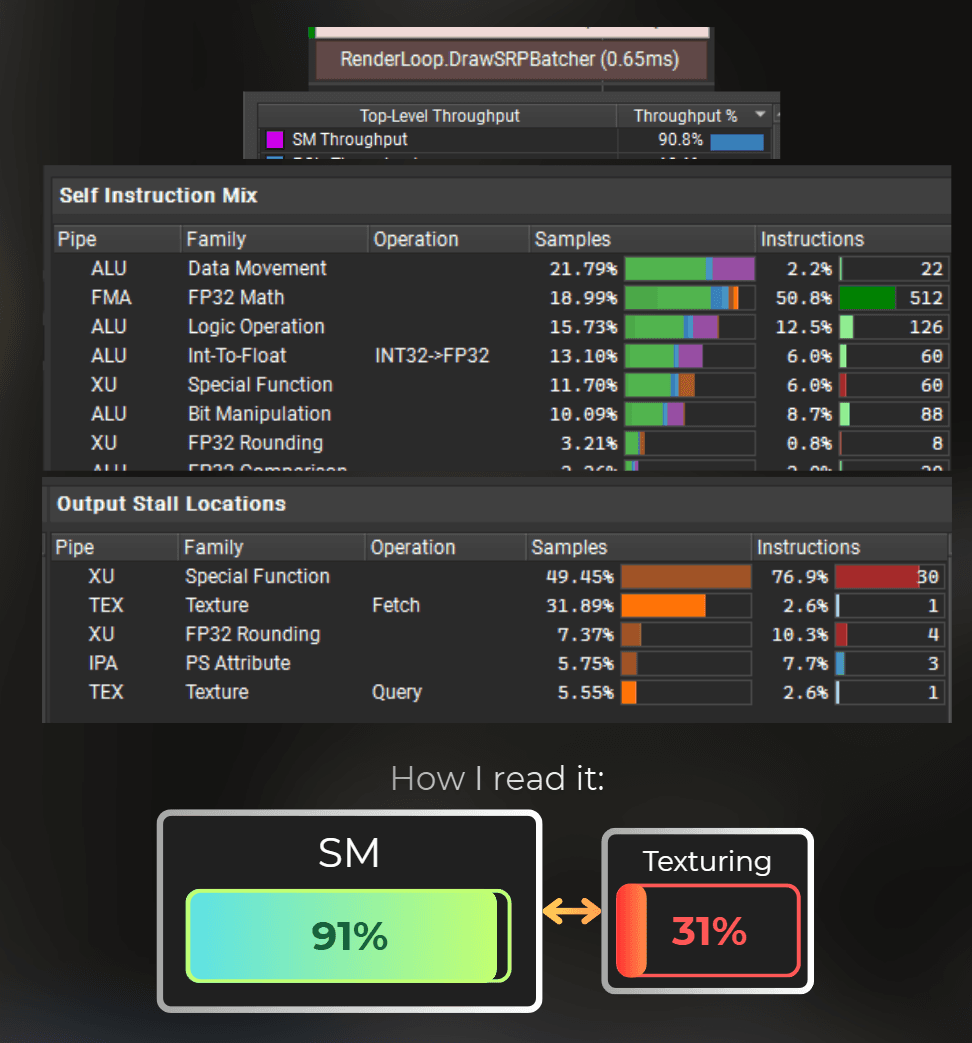
And those are the measurements. The shader executes in 0.59ms. It is already 0.43ms faster than the original shader.
___
Using ALU-based hash
Let's keep going with other ideas. Ampere architecture also has an ALU pipe responsible for integer calculations, like bitshifting, bitmasks, add, and multiply.
I want to check if switching the hash functions to ALU-based units would be faster. Those are the hash functions I came up with.
float FastHash1_2(float2 p)
{
uint2 n = asuint((p + 1.0921) * 642097u);
uint h = n.x;
h ^= n.y * 0x27d4eb2du;
h ^= h >> 15;
h *= 0x85ebca6bu;
h ^= h >> 13;
return (h & 0x00FFFFFFu) * (1.0 / 16777216.0);
}
float2 FastHash2_2(float2 p)
{
uint2 n = asuint(p * 628697u);
uint h1 = n.x ^ (n.y << 1) ^ 0x7f4a7c15u;
h1 *= 0x27d4eb2du;
h1 ^= h1 >> 15;
uint h2 = n.y ^ (n.x << 1) ^ 0xba55c0d3u;
h2 *= 0x165667b1u;
h2 ^= h2 >> 16;
float to01 = 1.0 / 4294967296.0;
return float2(h1, h2) * to01
float FastHash1_2(float2 p)
{
uint2 n = asuint((p + 1.0921) * 642097u);
uint h = n.x;
h ^= n.y * 0x27d4eb2du;
h ^= h >> 15;
h *= 0x85ebca6bu;
h ^= h >> 13;
return (h & 0x00FFFFFFu) * (1.0 / 16777216.0);
}
float2 FastHash2_2(float2 p)
{
uint2 n = asuint(p * 628697u);
uint h1 = n.x ^ (n.y << 1) ^ 0x7f4a7c15u;
h1 *= 0x27d4eb2du;
h1 ^= h1 >> 15;
uint h2 = n.y ^ (n.x << 1) ^ 0xba55c0d3u;
h2 *= 0x165667b1u;
h2 ^= h2 >> 16;
float to01 = 1.0 / 4294967296.0;
return float2(h1, h2) * to01
float FastHash1_2(float2 p)
{
uint2 n = asuint((p + 1.0921) * 642097u);
uint h = n.x;
h ^= n.y * 0x27d4eb2du;
h ^= h >> 15;
h *= 0x85ebca6bu;
h ^= h >> 13;
return (h & 0x00FFFFFFu) * (1.0 / 16777216.0);
}
float2 FastHash2_2(float2 p)
{
uint2 n = asuint(p * 628697u);
uint h1 = n.x ^ (n.y << 1) ^ 0x7f4a7c15u;
h1 *= 0x27d4eb2du;
h1 ^= h1 >> 15;
uint h2 = n.y ^ (n.x << 1) ^ 0xba55c0d3u;
h2 *= 0x165667b1u;
h2 ^= h2 >> 16;
float to01 = 1.0 / 4294967296.0;
return float2(h1, h2) * to01
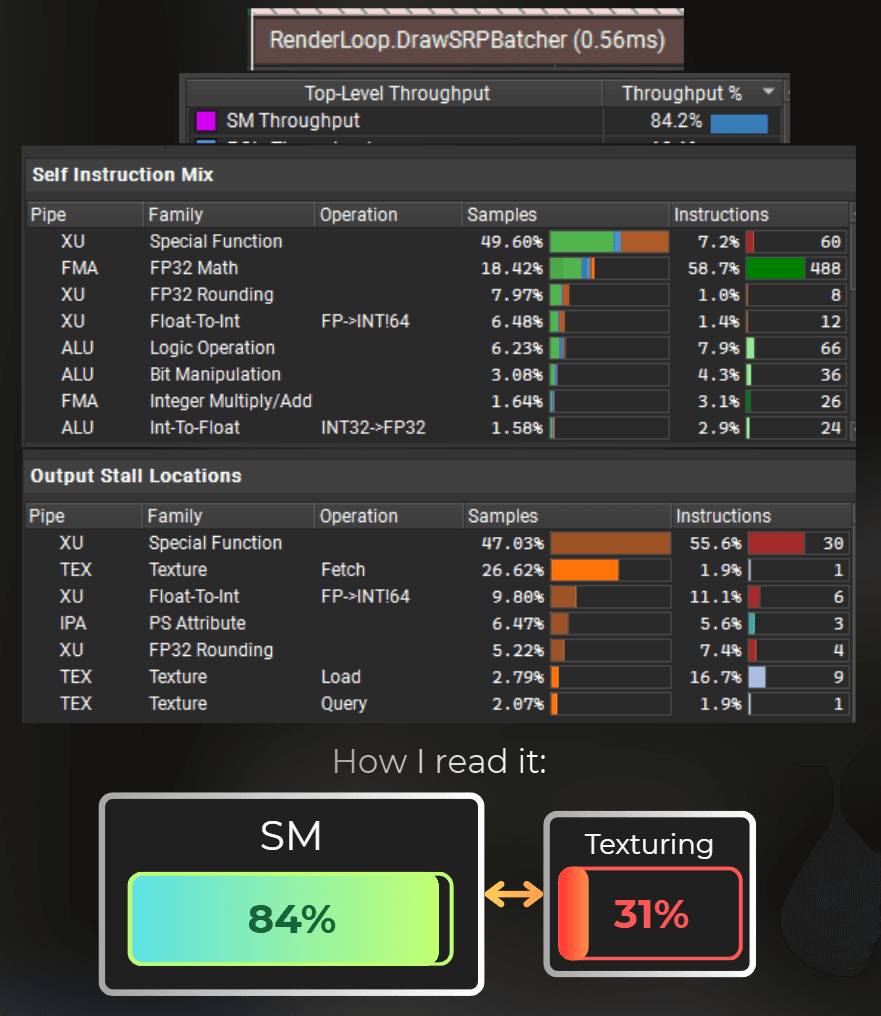
I replaced all the hash functions used in the Voronoi noise with the functions above. Texturing units are still underutilized in this case, but special functions are no longer a bottleneck.
Also, the shader started to be slower than the previous version.
___
Balancing the SM and TEX workload
Now, I have a hash function that is running on ALU or TEX units. To balance the workload of this shader, I will use an ALU-based hash in one place and a TEX-based one in others.
I did some iterations and found that just after switching one ALU hash function to the TEX hash function, everything runs faster.
So, there is a new record! 0.56ms per frame. It is almost 2x as fast as the original shader. But let's keep going!
![[013-21-profileBalancedWorkload.png]]
___
Optimizing the length() function
The shader is still bound to Special Functions. Those are functions like sin, cos, and sqrt. But the Voronoi function uses a length function to calculate the distance from the cell center to the current UV.
Notice that the math equation behind the length calculation involves one square root, which is a special function. This is the current code.
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDist = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * FastHash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float dist = length(uv - p);
if (dist < minDist)
minDist = dist;
}
}
return minDist
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDist = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * FastHash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float dist = length(uv - p);
if (dist < minDist)
minDist = dist;
}
}
return minDist
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDist = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * FastHash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float dist = length(uv - p);
if (dist < minDist)
minDist = dist;
}
}
return minDist
I modified this code to use a squared distance instead:
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * FastHash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float2 toCellCenter = uv - p;
float distSq = dot(toCellCenter, toCellCenter);
if (distSq < minDistSq)
minDistSq = distSq;
}
}
return sqrt(minDistSq
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * FastHash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float2 toCellCenter = uv - p;
float distSq = dot(toCellCenter, toCellCenter);
if (distSq < minDistSq)
minDistSq = distSq;
}
}
return sqrt(minDistSq
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi);
float d = _Time.y * FastHash1_2(r) * ANIMATION_SPEED;
float2 p = VoronoiPointFromRoot(r, d);
float2 toCellCenter = uv - p;
float distSq = dot(toCellCenter, toCellCenter);
if (distSq < minDistSq)
minDistSq = distSq;
}
}
return sqrt(minDistSq
So I moved the square root operation out of the for loop. And it is another 0.03ms shaved!
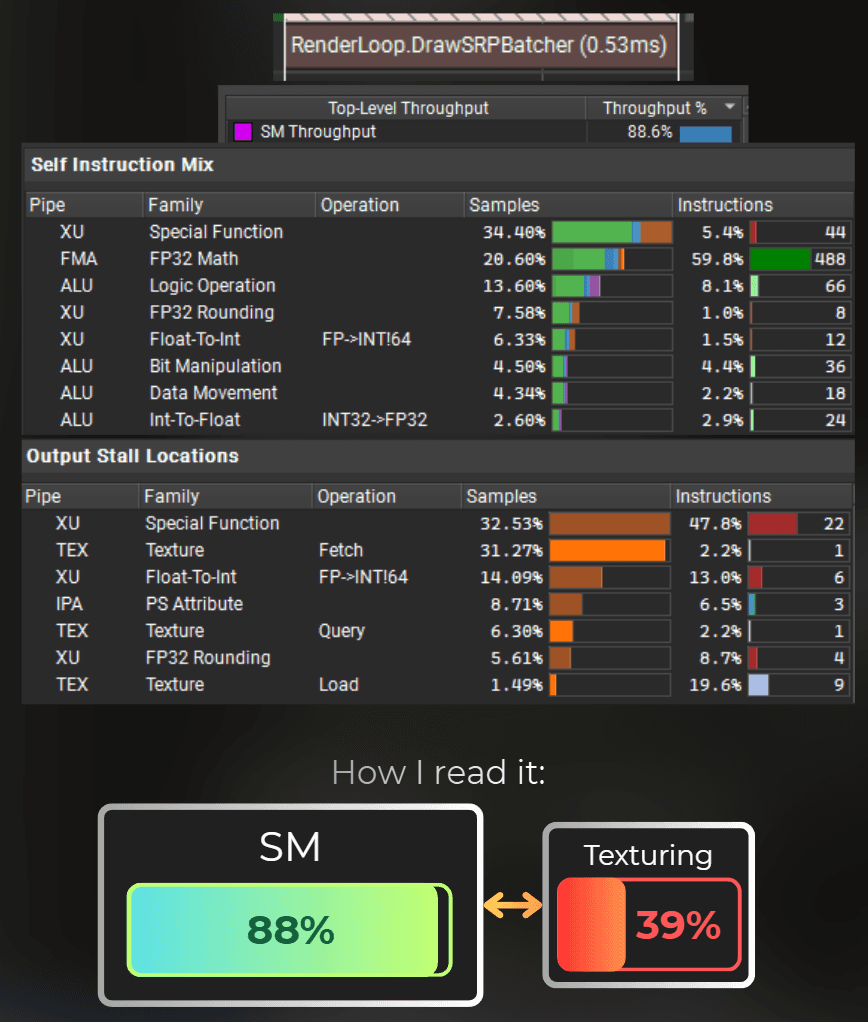
And now, I'm still special-function bound...
___
Optimizing the sin and cos functions with FP32
Each Voronoi cell uses a sine and cosine function to randomly rotate the cell center.
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
My idea is to use a texture or a prebaked lookup table in the shader to speed them up. To be honest, I never thought about optimizing such functions, but here we go!
It is important for me that these sin and cos are used here to animate a single point, so it doesn't really need to be mathematically correct. I experimented a little and used a fractional part of the float, then some polynomial, and there we go. My custom sine and cosine functions:
float SmoothFunction(float t)
{
return t * t * (3.0 - 2.0 * t);
}
float FPCos(float t)
{
t /= PI * 2.0;
float f = SmoothFunction(abs(frac(t) - 0.5) * 2.0) * 2.0 - 1.0;
return f;
}
float FPSin(float t)
{
t /= PI * 2.0;
t += 0.25;
float f = SmoothFunction(abs(frac(t) - 0.5) * 2.0) * -2.0 + 1.0;
return f
float SmoothFunction(float t)
{
return t * t * (3.0 - 2.0 * t);
}
float FPCos(float t)
{
t /= PI * 2.0;
float f = SmoothFunction(abs(frac(t) - 0.5) * 2.0) * 2.0 - 1.0;
return f;
}
float FPSin(float t)
{
t /= PI * 2.0;
t += 0.25;
float f = SmoothFunction(abs(frac(t) - 0.5) * 2.0) * -2.0 + 1.0;
return f
float SmoothFunction(float t)
{
return t * t * (3.0 - 2.0 * t);
}
float FPCos(float t)
{
t /= PI * 2.0;
float f = SmoothFunction(abs(frac(t) - 0.5) * 2.0) * 2.0 - 1.0;
return f;
}
float FPSin(float t)
{
t /= PI * 2.0;
t += 0.25;
float f = SmoothFunction(abs(frac(t) - 0.5) * 2.0) * -2.0 + 1.0;
return f
Here, I plotted the GPU sin and cos in red, and my functions in green. They match pretty accurately for my needs.
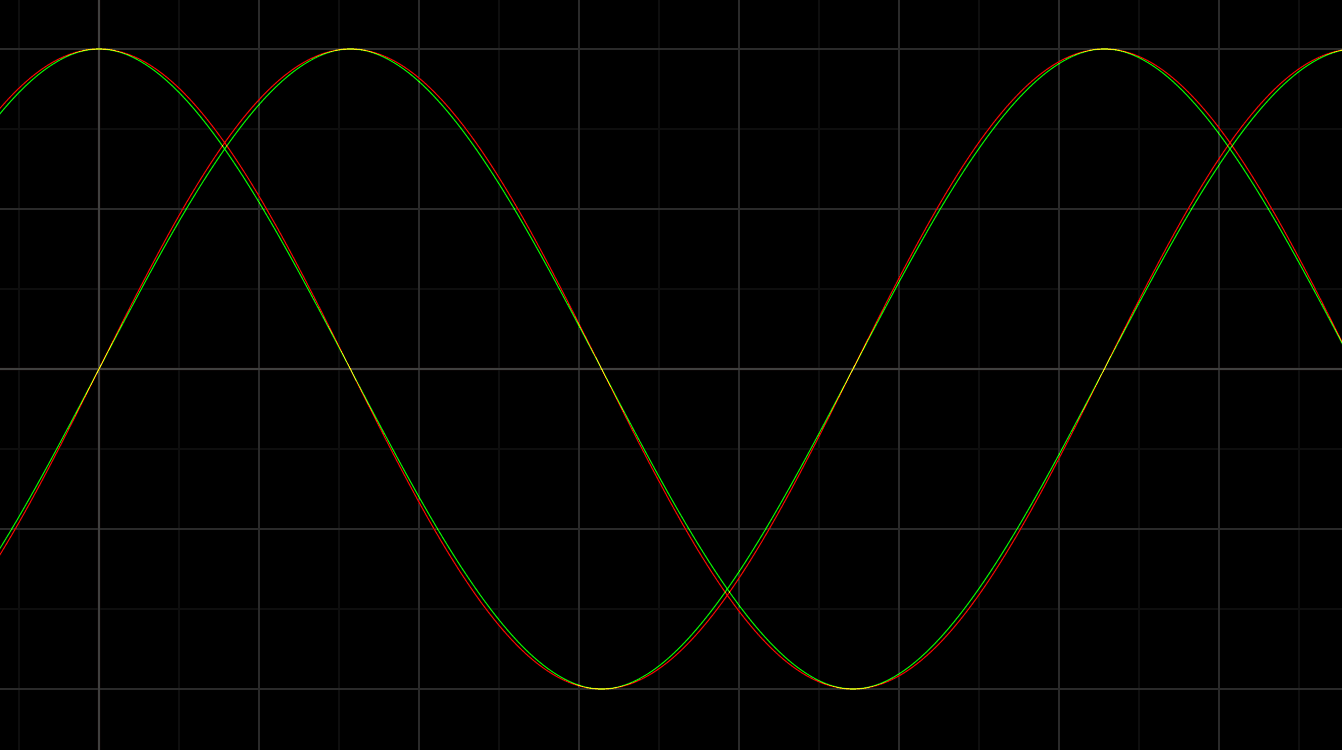
And I replaced them in the shader code.
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s = FPSin(deg);
float c = FPCos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s = FPSin(deg);
float c = FPCos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s = FPSin(deg);
float c = FPCos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
And... My functions are slower! Tbh, it is kind of satisfying that the special functions like cos and sin are optimized to the limits by the GPU. I would be really worried if I could just write my own sine and cosine, and it would be faster. 😂
Nonetheless, it was a good experiment. It shows that I traded sin/cos functions for number rounding, which is still a special function.
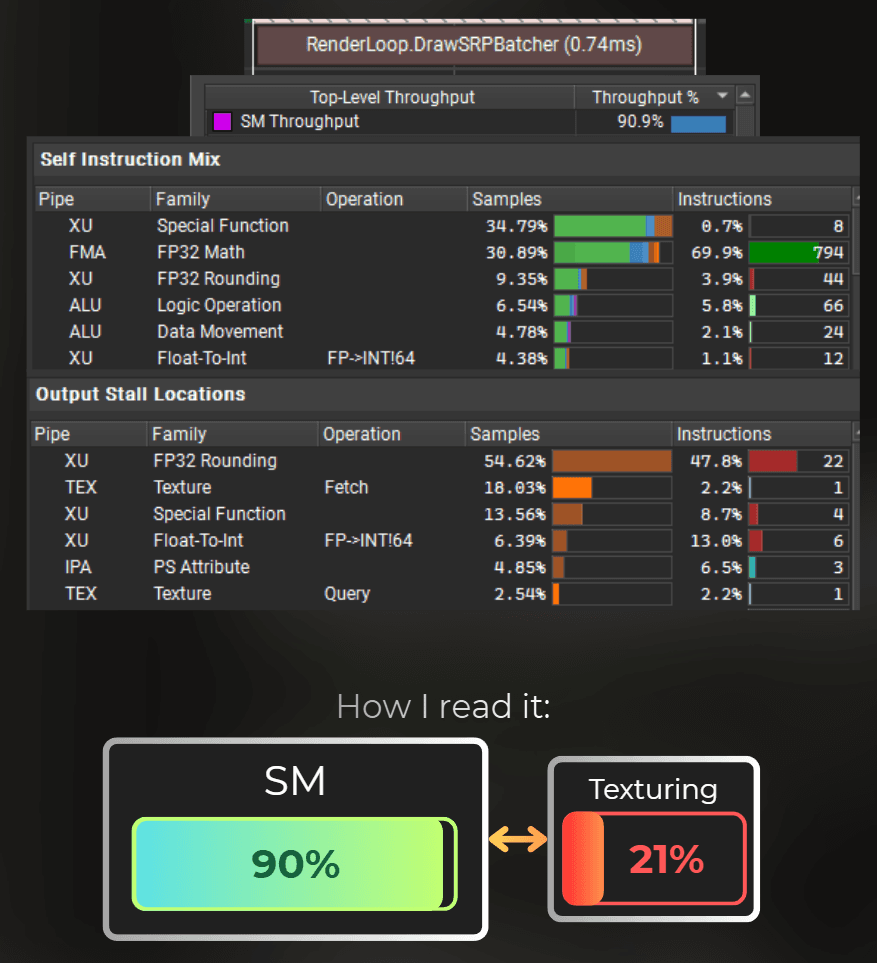
___
Optimizing sin and cos functions using TEX
Ok, so I failed at optimizing special functions using FP32. Let's try it with TEX units.
I will bake the sin/cos results into a texture and try to use a LUT for those calculations. I created this C# script. It bakes the texture asset:
const int width = 128;
var tex = new Texture2D(width, 4, TextureFormat.RGBA32, false);
for (int x = 0; x < width; x++)
{
float t = (float)x / (width - 1);
float angle = t * Mathf.PI * 2f;
float s = (Mathf.Sin(angle) + 1f) * 0.5f;
float c = (Mathf.Cos(angle) + 1f) * 0.5f;
tex.SetPixel(x, 0, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 1, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 2, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 3, new Color(s, c, 0.0f, 1.0f));
}
tex.Apply();
var path = "Assets/SinCosLUT.png";
File.WriteAllBytes(path, tex.EncodeToPNG());
AssetDatabase.Refresh
const int width = 128;
var tex = new Texture2D(width, 4, TextureFormat.RGBA32, false);
for (int x = 0; x < width; x++)
{
float t = (float)x / (width - 1);
float angle = t * Mathf.PI * 2f;
float s = (Mathf.Sin(angle) + 1f) * 0.5f;
float c = (Mathf.Cos(angle) + 1f) * 0.5f;
tex.SetPixel(x, 0, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 1, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 2, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 3, new Color(s, c, 0.0f, 1.0f));
}
tex.Apply();
var path = "Assets/SinCosLUT.png";
File.WriteAllBytes(path, tex.EncodeToPNG());
AssetDatabase.Refresh
const int width = 128;
var tex = new Texture2D(width, 4, TextureFormat.RGBA32, false);
for (int x = 0; x < width; x++)
{
float t = (float)x / (width - 1);
float angle = t * Mathf.PI * 2f;
float s = (Mathf.Sin(angle) + 1f) * 0.5f;
float c = (Mathf.Cos(angle) + 1f) * 0.5f;
tex.SetPixel(x, 0, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 1, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 2, new Color(s, c, 0.0f, 1.0f));
tex.SetPixel(x, 3, new Color(s, c, 0.0f, 1.0f));
}
tex.Apply();
var path = "Assets/SinCosLUT.png";
File.WriteAllBytes(path, tex.EncodeToPNG());
AssetDatabase.Refresh
And this is the texture I got from running the script. It takes 1KB, so it will fit entirely in L1 cache.
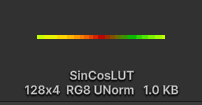
I modified the shader code to use this texture lookup instead. My idea is that it should run faster because the texturing units will perform a frac operation to wrap the texture, so it will be delegated to a different unit. Let's see how it works.
void TEXSinCos(float rad, out float out_sin, out float out_cos)
{
float2 sc = _SinCosLUT.SampleLevel(linearRepeatSampler, float2(rad / (PI * 2.0), 0.125), 0.0).xy;
out_sin = sc.x;
out_cos = sc.y;
}
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s, c;
TEXSinCos(deg, s, c);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
void TEXSinCos(float rad, out float out_sin, out float out_cos)
{
float2 sc = _SinCosLUT.SampleLevel(linearRepeatSampler, float2(rad / (PI * 2.0), 0.125), 0.0).xy;
out_sin = sc.x;
out_cos = sc.y;
}
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s, c;
TEXSinCos(deg, s, c);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
void TEXSinCos(float rad, out float out_sin, out float out_cos)
{
float2 sc = _SinCosLUT.SampleLevel(linearRepeatSampler, float2(rad / (PI * 2.0), 0.125), 0.0).xy;
out_sin = sc.x;
out_cos = sc.y;
}
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash2_2(root) - 0.5) * 0.71;
float s, c;
TEXSinCos(deg, s, c);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
So it runs faster than the FP32 version, but still 0.10ms slower than the optimized shader before. Now that the shader is TEX-saturated, the SM units' efficiency has decreased.
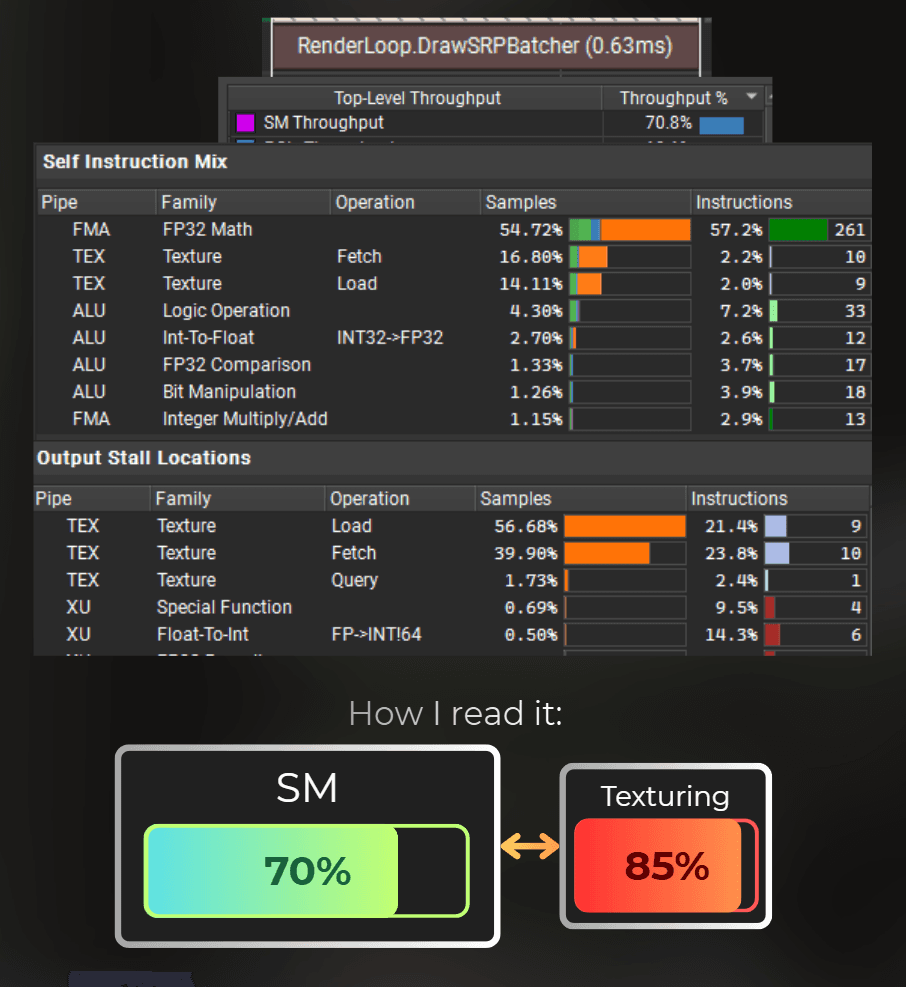
I tried to balance the SM and TEX workloads by swapping ALU hashes for TEX hashes, but I couldn't make it any faster than this.
Finally, I reverted all the changes to the moment where the shader was running in 0.53ms. To be honest, it was reassuring that I wasn't able to make my trigonometry functions run faster than the built-in ones.
___
Loop unrolling and simplifying randomness
While browsing the code, I noticed that one loop doesn't have forced unrolling. So I added the unrolling attribute. It will force the compiler to execute this loop at compile-time and produce the consecutive instructions, entirely skipping the loop control flow.
[unroll]
for (int i = 0; i < layers; i++)
{
float2 offs = (((i + 1.0) / layers)) * 0.5 * _Time.y * WATER_SPEED
[unroll]
for (int i = 0; i < layers; i++)
{
float2 offs = (((i + 1.0) / layers)) * 0.5 * _Time.y * WATER_SPEED
[unroll]
for (int i = 0; i < layers; i++)
{
float2 offs = (((i + 1.0) / layers)) * 0.5 * _Time.y * WATER_SPEED
I also noticed that each Voronoi cell computes a random cell position, which is then rotated. But if the rotation angle is random, I don't need a full random 2D vector. In this case, I replaced TextureHash2_2 with TextureHash1_2. I doubt it changed the shader's performance, since it still needs to sample the same texture. Let's keep this change anyway.
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash1_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash1_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash1_2(root) - 0.5) * 0.71;
float s = sin(deg);
float c = cos(deg);
p = mul(p, float2x2(s, c, -c, s));
return p + root + 0.5
And because the loop is unrolled now, the shader runs faster. New record, 0.03ms improvement, compared to the previous best result.
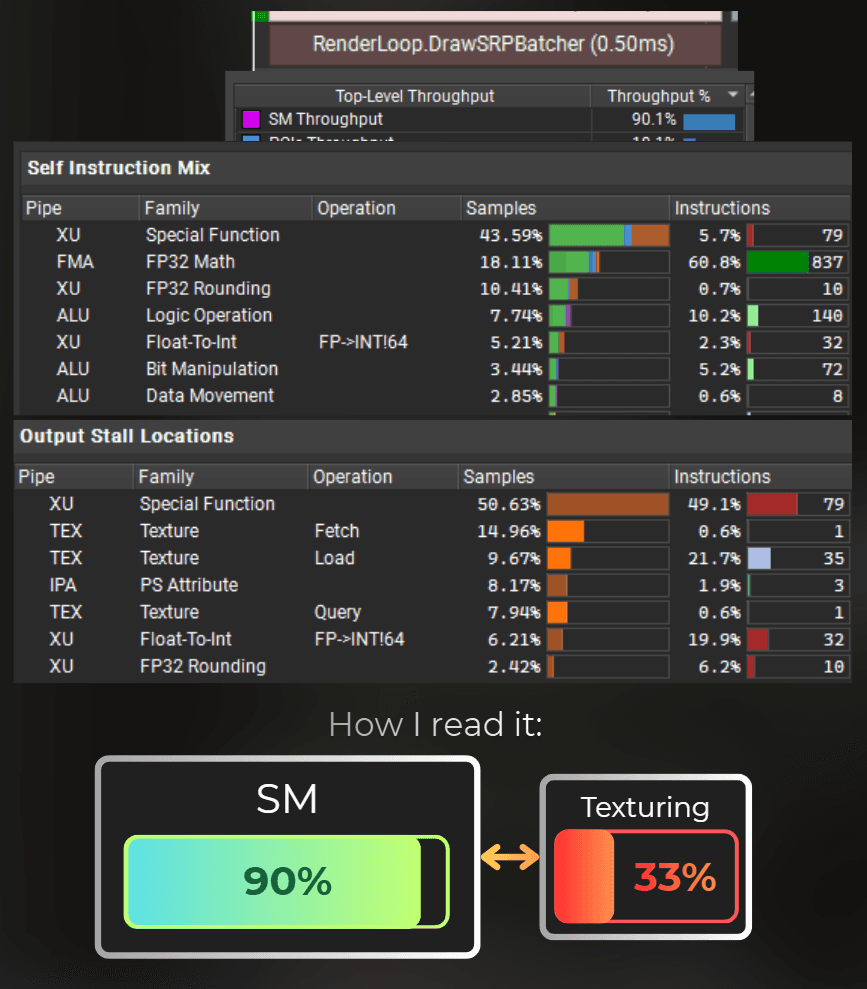
Currently this is the optimized shader (0.50ms)
___
Reducing Voronoi complexity
Now I don't have any more ideas for optimizing this shader further, except for those that would reduce its quality.
My main idea is to reduce the size of the Voronoi noise window. Voronoi works by iterating through nearby square cells. Each cell has a randomized center position. Voronoi returns the distance from the UV to the closest cell center. Usually, a 3x3 window is used.
However, I can modify the algorithm to use a 2x2 window instead:
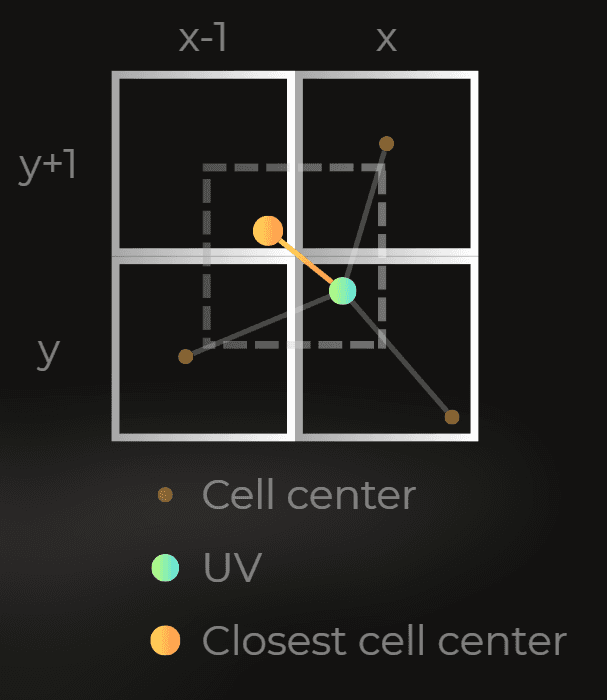
I will modify this code:
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 1; xi++)
{
[unroll]
for (int yi = -1; yi <= 1; yi++)
{
float2 r = rootUV + float2(xi, yi
I shifted the Voronoi window by 0.5 to ensure I am still at the window center. Then I limited the window size to 2x2.
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv + 0.5);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 0; xi++)
{
[unroll]
for (int yi = -1; yi <= 0; yi++)
{
float2 r = rootUV + float2(xi, yi
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv + 0.5);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 0; xi++)
{
[unroll]
for (int yi = -1; yi <= 0; yi++)
{
float2 r = rootUV + float2(xi, yi
float Voronoi(float2 uv)
{
float2 rootUV = floor(uv + 0.5);
float minDistSq = 2.0;
[unroll]
for (int xi = -1; xi <= 0; xi++)
{
[unroll]
for (int yi = -1; yi <= 0; yi++)
{
float2 r = rootUV + float2(xi, yi
I also needed to limit the randomness of the generated cell centers. I reduced the max length of the random vector by multiplying it by a smaller number.
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash1_2(root) - 0.5) * 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash1_2(root) - 0.5) * 0.5
float2 VoronoiPointFromRoot(float2 root, float deg)
{
float2 p = (TextureHash1_2(root) - 0.5) * 0.5
And the render time dropped to 0.28ms.
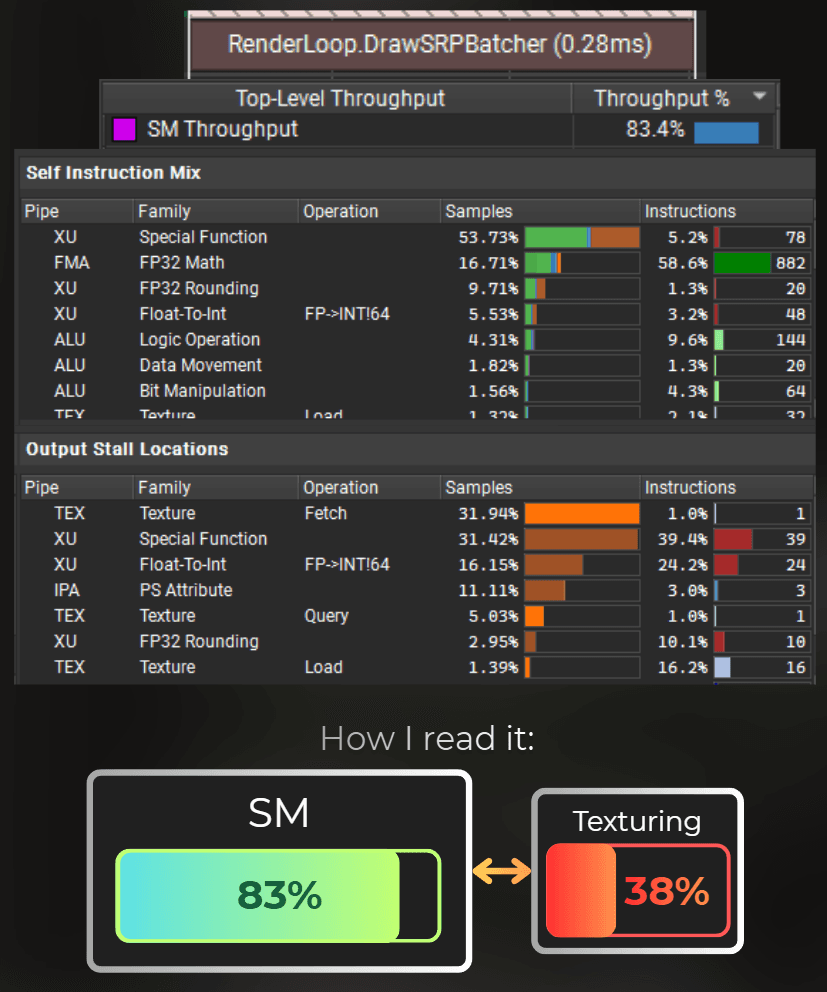
___
Reducing the effect's layer count
Right now, the effect looks almost identical to the original. The last thing I can do is limit the maximum noise layer count. Here, I reduced the layer count from 4 to 3.
The render time dropped to 0.21ms.
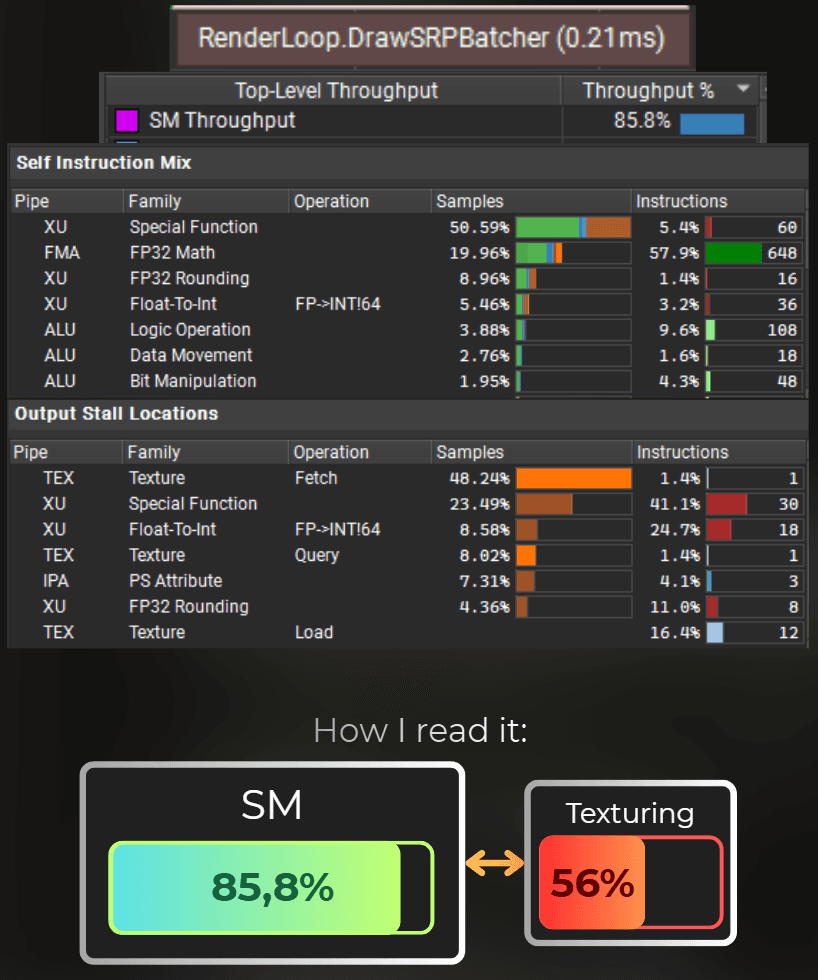
___
Summary
This is the original shader: 1.02ms / frame
And this is the optimized one: 0.21ms / frame.
About 5x faster.
What I did
I moved part of the work into look-up-textures, for hash functions and value-noise. It allowed the GPU to process the shader across the ALU and TEX units simultaneously.
I changed the hash functions to use bit operations instead of sine and frac. This saved time spent on special functions.
I optimized the shader further by making Voronoi use squared distance instead of the distance.
I introduced loop unrolling.
I changed the Voronoi window from 3x3 to 2x2.
I reduced the layer count of the effect from 4 to 3.
Those optimizations made the shader run 5x faster than the original one.
The optimized shader source code: GlareOfWater-Optimized.shader
The original one: GlareOfWater-Original.shader
Did you like it?
This LinkedIn post is a good place to discuss about the case study in this article.
Follow me on LinkedIn, where I share rendering and optimization insights, weekly.
:center-px:
You may also like:
VRAM bandwidth and its big role in optimization
How to profile the rendering - GPU profiling basics


