Profiling
Tech-Art
Rendering
Future of graphics programming - GIC Katowice panel summary
10 min

I was a guest on the AUA panel "The Future of Game Rendering: Path-Tracing, Neural, and Beyond" at GIC Katowice, together with Łukasz Bogaczyński (AMD) and Peter Sikachev (AMD), moderated by Radosław Paszkowski (That Shader Guy / PixelAnt Games).
The panel description set the tone pretty well: the graphics landscape is shifting and graphics programmers are just starting to grasp real-time ray-tracing in games, and there is already another mountain of new features waiting: Neural <put here anything> backed up by the large, arbitrary size matrix multiplication that will be soon supported in compute, vertex/fragment and other shaders.
The idea of the panel was to look into a bit of a crystal ball, discuss what graphics programming means today, and talk through the growing challenges facing modern games.
This article is my own summary of that discussion and also other discussions I had during this event, written from notes I made on the train while heading back from the event. It is not a transcript, and it does not represent the official position of AMD, The Knights of U, or PixelAnt Games - just my personal take on what we talked about, grouped by topic and written the way I usually think about this stuff.
Some of the points here also came from various conversations I had during the event.
Thanks to Łukasz Bogaczyński, Peter Sikachev, and Radosław Paszkowski for a great discussion on stage - and especially to Radosław for inviting me as a guest.

In this article:
What raytracing actually is today and why mobile is a different planet.
Why we still ship DX11 alongside DX12 - the first era of API coexistence.
Who can afford RT and neural rendering.
The neural rendering pipeline gap nobody talks about enough.
Education, entry level, and disappearing fundamentals.
Performance culture, stonks-driven engines, and asset import complexity.
___
Raytracing is an algorithm stack, not a hardware feature
This was one of the strongest themes on the panel.
We explained the difference between raytracing and path tracing in real-time rendering, since it is not the same distinction used in offline rendering.
Raytracing:
The game uses classic rasterization, but uses raytracing as a "support" for some of the effects, like GI.
Path tracing:
We say "path tracing" if the rasterization part is skipped, and everything visible on the screen uses raytracing to drive the geometry rendering.
___
Current raytracing performance
For "real" path tracing we would need to cast thousands or even millions of rays per pixel, including the indirect light bounces to make the image look smooth.
Currently we can use up to 1-2 rays per pixel. That is still far below what we need to make "real" raytracing happen.
Raytracing isn't possible just because the hardware finally got strong enough. It's possible because graphics programming took a huge leap in caching, virtualization, and smart ray reuse/prediction, and the hardware became fast enough to run those ideas in real time.
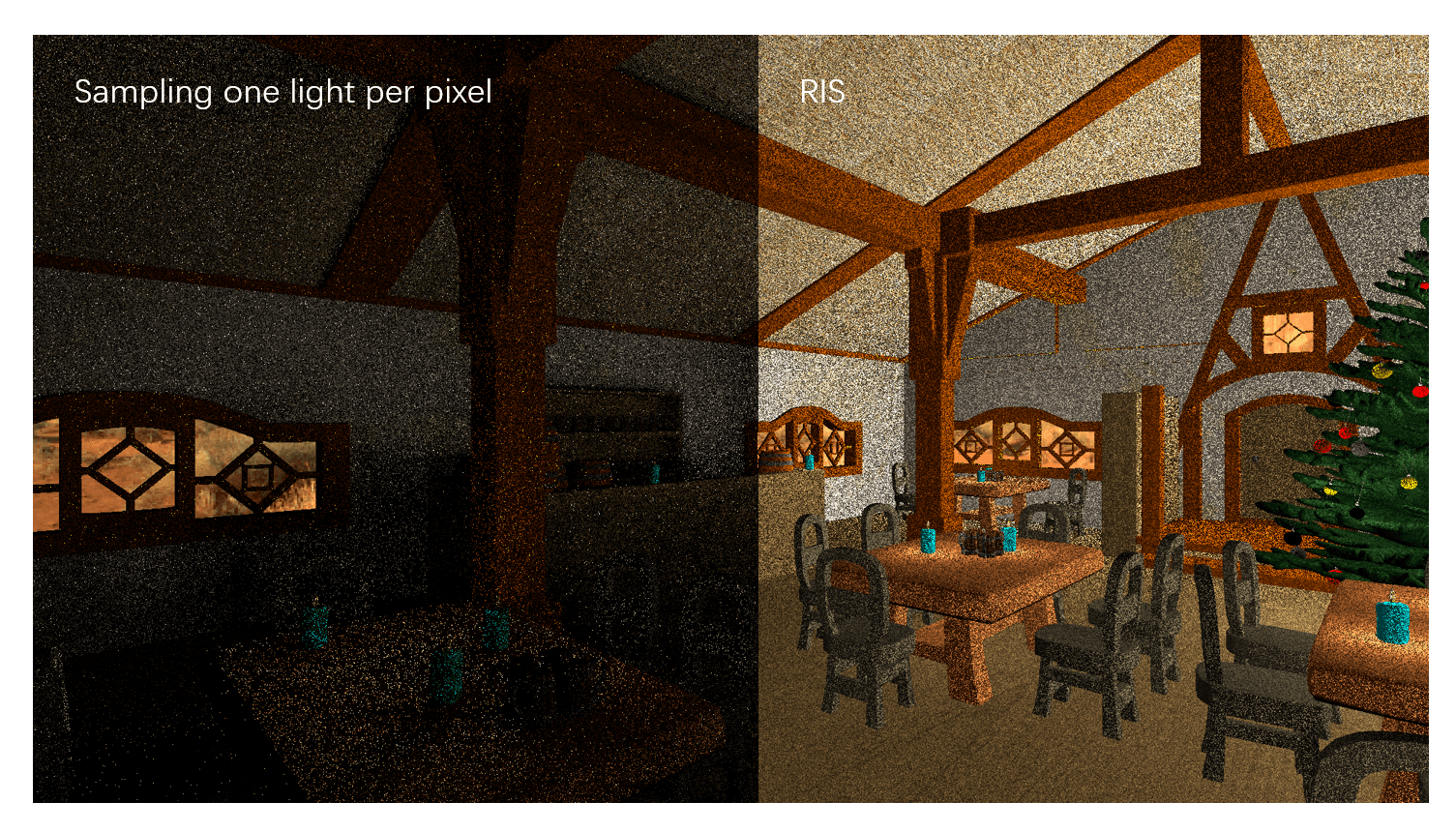
Source: https://github.com/lindayukeyi/ReSTIR_DX12
Pipelines that utilize raytracing usually run at about 1-2 rays per pixel per frame. But they are able to converge into a good looking image thanks to advanced tech stack: spatial caching, screen-space caching, ray prediction, denoising, upscaling, and sometimes frame generation on top. Those pipelines are becoming hard to control and understand, precisely because so many layers work together to turn a sparse signal into a stable image.
___
Future of raytracing
Raytracing is not simple. It will be a long time before smaller or less experienced teams can develop with it comfortably. This stuff requires a lot of graphics programming experience, and the entry level for that is high.
Raytracing is built heavily around temporal stability and a complex tech stack that resolves that "noise" into a stable image over time.

Source: https://github.com/IwakuraRein/CIS-565-Final-VR-Raytracer
Because of that, we expect most teams will rely on simpler "support" effects that utilize raytracing. For example:
some mirror reflections
real-time baking/virtualization of light probes used in a classic raster pipeline
We also mentioned raytracing on mobile. ARM recently unveiled a new demo, ARM Neural Dawn, built with neural upscaling and frame generation. Based on ARM's own numbers, my rough estimate is that the whole stack works out to something like 1/4 or 1/8 rays per native pixel in the rendered frame, upscaling and framegen included. The results are extremely noisy, so they get accumulated over multiple frames. A neural network trained specifically for that game handles the denoising.
Raytracing may become a standard for AAA and AA games, but smaller teams, unless they have a really passionate and skilled graphics programmer, will have a real challenge implementing custom raytracing paths.
Raytracing is fairly new and it needs to beat 30-40 years of development in raster rendering. Not something that will happen fast. It is still impressive that you can render a raytraced image with a budget of just a few rays per pixel.
___
Mobile and PC are drifting apart
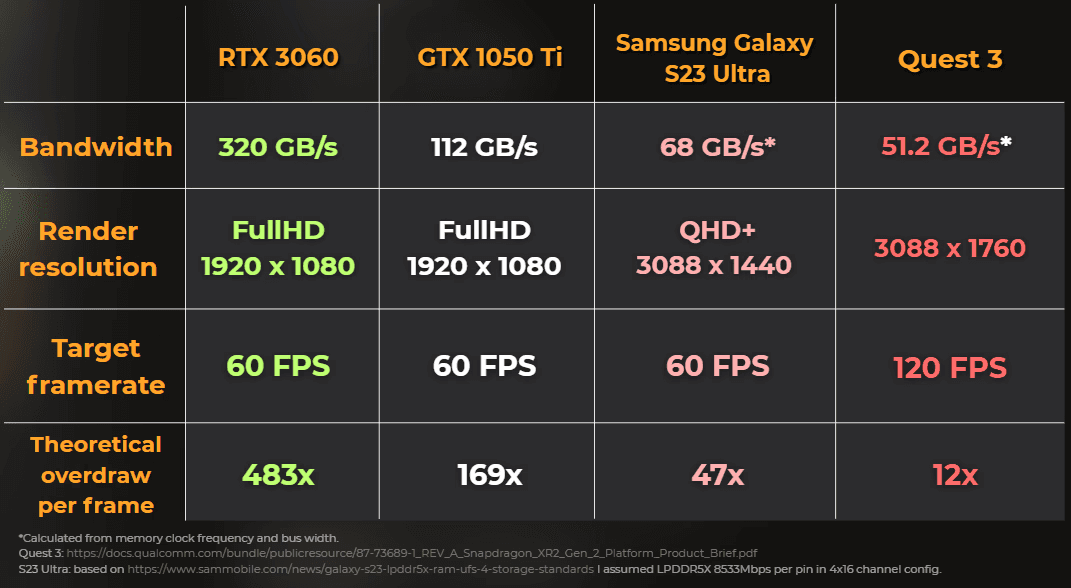
The median PC GPU is still around RTX 3060 class hardware - released about five years ago. A lot of teams develop on much stronger machines and never feel the cost of their rendering decisions until porting or testing on target hardware. That gap between "what we develop on" and "what we ship to" keeps getting wider, especially between PC and mobile.
Mobile and PC hardware are heading in slightly different directions.
Look at the comparison in real numbers:
Source: https://www.proceduralpixels.com/blog/vram-bandwidth-and-its-big-role-in-optimization
Raytracing relies heavily on resolving cache misses quickly. On PC you might have:
Power supply of 500-1000W for the whole system
Temperatures up to 100 C.
Active cooling
300-500 GB/s VRAM bandwidth, up to around 1.8 TB/s on high-end
On mobile, we're working within much tighter hardware limits:
Power supply of 3-12W (100x lower)
Hard thermal ceiling because the device is in your hands, can't exceed 45 C.
No active cooling
Memory shared with the CPU
VRAM bandwidth: ~30 GB/s mid-range and ~80 GB/s high-end (10-20x slower)
Most of the heat is generated by memory transfers: cache operations, fetching register data, resolving cache misses, saving into VRAM. Mobile keeps getting faster on compute, but lags behind on cache and RAM performance.
Raytracing relies on quickly resolving cache misses. Since cache misses are the main source of heat generation, it may take a long time before raytracing becomes practical as a render path on mobile.
Mobile will likely move toward neural rendering instead, where a small neural network close to the GPU registers can solve problems that would otherwise require heavy memory access. For example, game-trained neural reconstruction of very noisy RT results - like we saw in a new ARM demo.
___
Upscale and framegen on mobile

I expect that on mobile we will see more advanced upscale+framegen tech in the future, while compute capabilities are getting stronger.
But framegen has one trade-off - it introduces frames that are not directly driven by fresh player input, generated in between the real ones.
This combination makes framegen suitable only for a subset of games: slow-paced games, where input lag is not critical and camera speed and fast movements are limited.
Also upscaling often requires developers to modify the existing pipeline and render more targets. While on PC it is reasonable to add a motion vectors rendering, on mobile it is not that simple due to the memory bandwidth constraint. So mobile will probably advance more towards simpler denoisers and upscalers.
___
This is the first era where old graphics APIs were not abandoned
One thing we touched on during the panel, and that I think is easy to miss: this is probably the first time in graphics history where the previous generation of APIs did not get dropped when the new one arrived.
When the industry moved from DirectX 9 to DirectX 11, DX9 support did not stick around for long in new engines and new AAA titles. Same pattern earlier with fixed-function to programmable pipelines, or OpenGL 2.x to 3.x core profile - the old path got cut, teams migrated, and the ecosystem moved on.
DirectX 12 and Vulkan broke that pattern.
Today, most major engines ship both DX11 and DX12. Same with Vulkan, because OpenGL is still there as a fallback on many platforms - even though OpenGL has not had a meaningful major update in roughly 8 years (OpenGL 4.6 landed in 2017 and that was basically it).
So instead of one API replacing another, we accumulated a stack of coexisting backends:
DX11 + DX12 on Windows
Vulkan + OpenGL on Linux and in cross-platform engines
Metal on Apple
Console-specific APIs on top of all that
Engines need a fallback path for production sanity. New APIs ship with driver bugs, missing features, and platform-specific edge cases. When raytracing, mesh shaders, or bindless resources misbehave on one backend, you want to fall back to the battle-tested immediate/compatibility layer rather than blocking a milestone because one vendor's driver regressed. This is especially visible on mobile and Vulkan support among different vendors. The device may say that "Vulkan is supported", but the ability to run your rendering without any issues is in question.
Maintaining multiple backends is expensive - every feature gets implemented twice (or three times), every bug gets debugged in multiple places, and every graphics programmer needs a wider mental model of the stack. But that cost may still be cheaper than abandoning a large chunk of your audience or betting the whole studio on a single immature API path.
On top of having more rendering features, we also keep more rendering APIs alive at the same time. That alone makes the stack feel heavier than before.
I can't wait to see the times when major engines finally drop the support for DX11 or OpenGL, and Vulkan and DX12 will be considered stable among all GPU and driver vendors.
___
Who actually gets RT and neural rendering?
For the next few years, RT and neural rendering with custom trained models will stay mostly in AAA and AA territory.

Source: Dying Light 2 - https://youtu.be/r9LtQhrHY24
Indie and smaller teams? Maybe a few passionate individuals will implement custom stylized rendering paths with RT and neural stuff. Most teams will rely on available pretrained solutions for common problems, because graphics programming gets more complex every year and very small teams have limited budget to own the whole stack.
Wide adoption of custom neural rendering in fragment, compute, and raytracing shaders is probably on a 5-7 year horizon, based on how long other rendering features took to go from "new hardware standard" to "used in shipped games."
___
What is neural rendering
The simplest networks in machine learning are just a series of matrix multiplications separated by a nonlinear activation function. Imagine you just multiply the matrix by the vector, and then ensure that minimum value in the result is not below 0. This is what tensor cores and other "matrix multiplication" cores are designed for. That is what will allow different studios to train their own machine learning models for their own rendering.
Neural rendering is just a hyped term for "multiplying a vector of arbitrary size by a matrix of arbitrary size". I like the term "linear algebra" better than "neural rendering", and it will be called Linear Algebra in the upcoming Shader Model 6.10
What will come in the next few years is much more efficient operations on large vectors and matrices that we can execute directly in the existing shader code, without writing a separate CUDA integration or other.
This is an average timeline of the GPU features development we observed in the past few years:
2-3 years: a small collection of games using it as tech-demo-level showcases.
~3 years: experimental adoption in engines.
~5 years: marked as stable in popular engines.
~7 years: widely adopted in released games.
We expect something similar to happen with "neural rendering."
___
Neural rendering needs infrastructure!
Neural rendering is real. Ubisoft already shipped neural compression in AC Mirage.
But I think nobody talks about the infrastructure problems it creates.
I built my own Ubisoft-style neural texture compression in Unity, running in fragment shaders, in about four evenings. So it is already more available than we think.
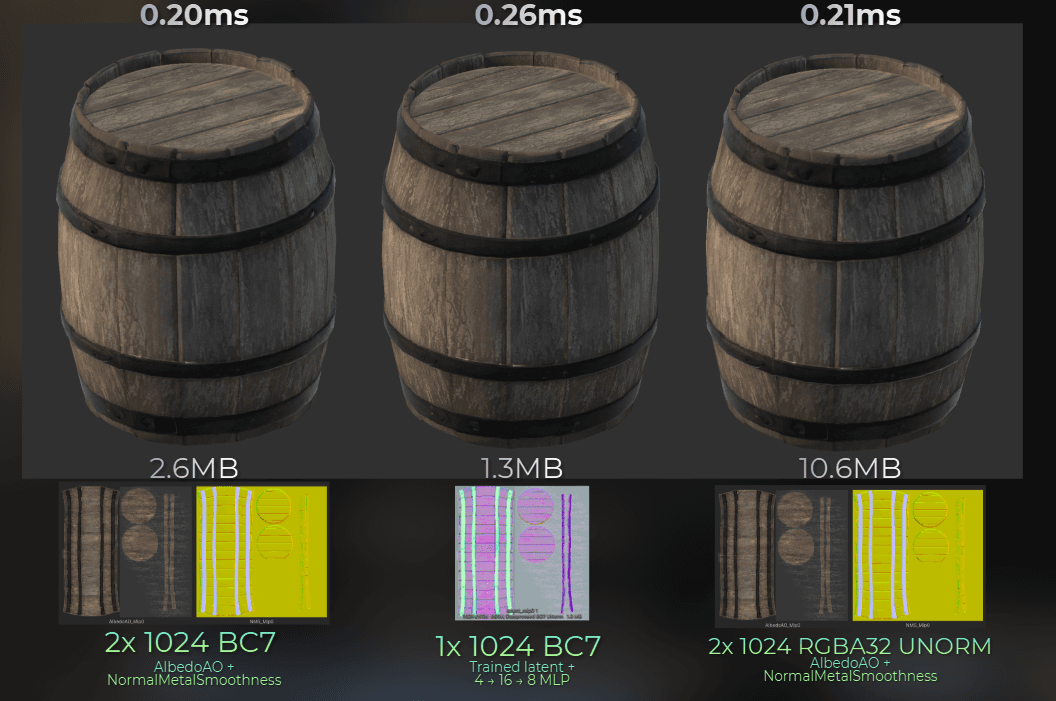
Source: My own implementation of neural compression
The core idea is like this:
We have a costly function that we need to execute at runtime.
We sample the function's arguments together with its results into a large training dataset.
We design a neural network (MLP) and train it to convert the arguments into good enough results.
We replace the costly function with the trained MLP.
So yes - you can do meaningful neural rendering on current hardware, even on FP32 cores, while we're waiting for the better native hardware support.
BUT production is a separate challenge.
What we need is an easy API to:
Build training data from rendered frames.
Train a small MLP.
Replace a function in the shader with that MLP.
That workflow doesn't really exist yet in a friendly form.
There are no libraries to build training sets on the GPU
Limited libraries for GPU-driven AI training in engines, or for using the graphics API directly for it
PyTorch training is slow for very small networks, and it requires a double implementation: one for Python training, one for the in-engine version
___
Neural compression as an example

Neural compression is a good example of this. You can think of neural compression like "I let the PC figure out custom compression format for each texture set individually", rather than "Compress this texture set using this algorithm"
Neural compression requires training the neural network and figuring out the source texture data. It can take 5-30 minutes per texture set. Import of a single texture set (albedo + normal + metalness + roughness + AO) goes from a few milliseconds to minutes.
To use this seriously, you need reliable asset import infrastructure: import once on one machine, distribute the result to every workstation in your studio, or ship MLP-ready content packs.
Even if the import time of a single texture is 5 minutes, you need to wait more than 24 hours to import 300 textures. Or have a 1 hour break if you dropped 12 new textures into your project.
Managing neural-dependent assets will be an internal challenge for every studio that wants this.
For training itself, current PyTorch implementations are inefficient for tiny MLP training. You probably need dedicated native compute paths for training really small networks, so you need to reimplement MLP training in your own compute shaders to make it reliably faster. Otherwise the authoring loop feels super slow.
So we are entering another data baking era, just at a higher level and with a higher skill ceiling.
At the party the day before the panel, I laughed that Unity will implement the neural compression and add "Texture import fee" just to import your texture in the cloud and bill the developers for each import they do, to make the imports quick.
Note to Unity: please, DON'T be inspired.
___
Education: harder to get hired, easier to experiment
Graphics programming has an extremely high entry level nowadays. In my experience, it can take a few years before you land a stable job in the field.

At the same time, you can start experimenting much more easily than before. Shader Graph, friendly engines, AI guidance - you can experiment with rendering and do really cool stuff without setting up a whole custom pipeline first.
That creates a weird split.
Ease of use makes basic knowledge disappear. You can become a technical artist without knowing the difference between a vertex shader and a fragment shader. Shader Graph lets you build something that compiles and works while you understand almost none of the fundamentals underneath. Fundamental knowledge has never been so easy to skip.
Advancement in technology requires advancement in skills. But in practice, it often makes developers lazier about performance control instead of pushing for more fidelity at the same performance. Engines advertise "performance out of the box" and "performance by default." That promise is hard to fully deliver in practice, because a larger tech stack requires more expertise to keep it under control.
If you are starting out today:
Prioritize learning fundamentals, get familiar with one graphics API and write your own renderer yourself.
Use books, like Real-Time Rendering or Game Engine Architecture to learn fundamentals.
Implement technology from scientific papers to "yoink" the way of thinking from other graphics programmers.
Have curiosity: "How does it work underneath?" in every step.
Prioritize having fun. It is a long run, so enjoy it!
Experiment freely with Shader Graph and AI tools, but do not let that replace fundamentals. Also don't outsource your thinking!

___
We forgot what fast workflows feel like
Engines are slow partly because we lost workflow performance control from the start. We only start caring when something takes more than 30 seconds and happens frequently. In reality, a lot of that could be almost instant - we just forgot how fast things can be and how fast computers are.
I would not blame the people here. Everybody wants to ship good games, and hardware keeps getting more complex every year, so it is harder to keep an intuitive feel for how fast things could actually be when you have different priorities.
I just wish that issues like "long assembly reload time", or "long time to launch the engine" could be taken more seriously. And that more developers report the issues like this, so we can keep the higher standards for the loading times and workflow sanity in engines and in our own projects and own tech stacks.

___
Stonks-driven development
Engines ship tech demos and experimental features designed for showcase, not production. It is a demo that shows "look, we are leading." It's rarely usable in a real shipping pipeline at the start. Lately we see a tendency to release features in "experimental" state without a clear plan for what happens next. Or abandoning new features after they were released. A few examples from Unity:
Unity's Project Tiny - allowing you to make really small builds.
HDRP shifted to maintenance-only - this is a big thing, as all the latest Unity demos were showcased using HDRP, and later Unity announced that there is no further development planned for HDRP.
Unity Behavior tree moved into maintenance-only (team was laid off, so the feature was "soft-abandoned")
Many experiments with networking, like UNet/HLAPI
Whole DOTS tech stack that was introduced in 2018 - it was evolving with many major API changes that changed the core workflow multiple times, and community observing the "damage control and re-stabilization focus" lately
Back to the demos: Demos show the engine from the good side only. As developers, we need the opposite too, since day 0: pain points, pitfalls, good practices, and examples of how bad it can get. We need real case scenarios to measure against, not ideal scenes built by a team that perfectly understands every limitation of the new system.
___
Bad demo example:
An example was Unity's water demo in HDRP, presented in 2023, where they said the water renders in 4ms in the demo scene on the current console generation, stating that it is "performant enough to run smoothly on various platforms":

Source: https://unity.com/blog/engine-platform/new-hdrp-water-system-in-2022-lts-and-2023-1
With current rendering complexity, we often talk about a rendering budget of 1-2ms per feature, and 2ms can already be a lot for some systems.
You need to fit a lot into the render pipeline: skinning, shadows, prepasses, GBuffer, transparency, GI virtualization, particle simulation, fluid simulation, raytracing, volumetrics, screen-space reflections, AO, postprocesses, upscaling, and more, 1ms can be a lot.
All those features need to fit under 16.66ms for 60FPS. If one of them takes 4ms, it is taking a quarter of your budget!
I will oversimplify this a bit, but if an engine has 20 high-end features underneath, and each of them is taking 4ms per frame - good luck picking up only 4 features that you can use to release your game!
Usually the pain points get addressed by engines later, after a few shipped games have already run into them first.
___
Importing one mesh was never this complicated
There have never been so many ways to import a single mesh as there are today.
Some time ago it was a vertex buffer, an index buffer, maybe separate data for collision. Now it can also be meshlets, Nanite geometry, voxelization, auto LOD generation, SDF acceleration structures, BLAS, surfels, GI faces...
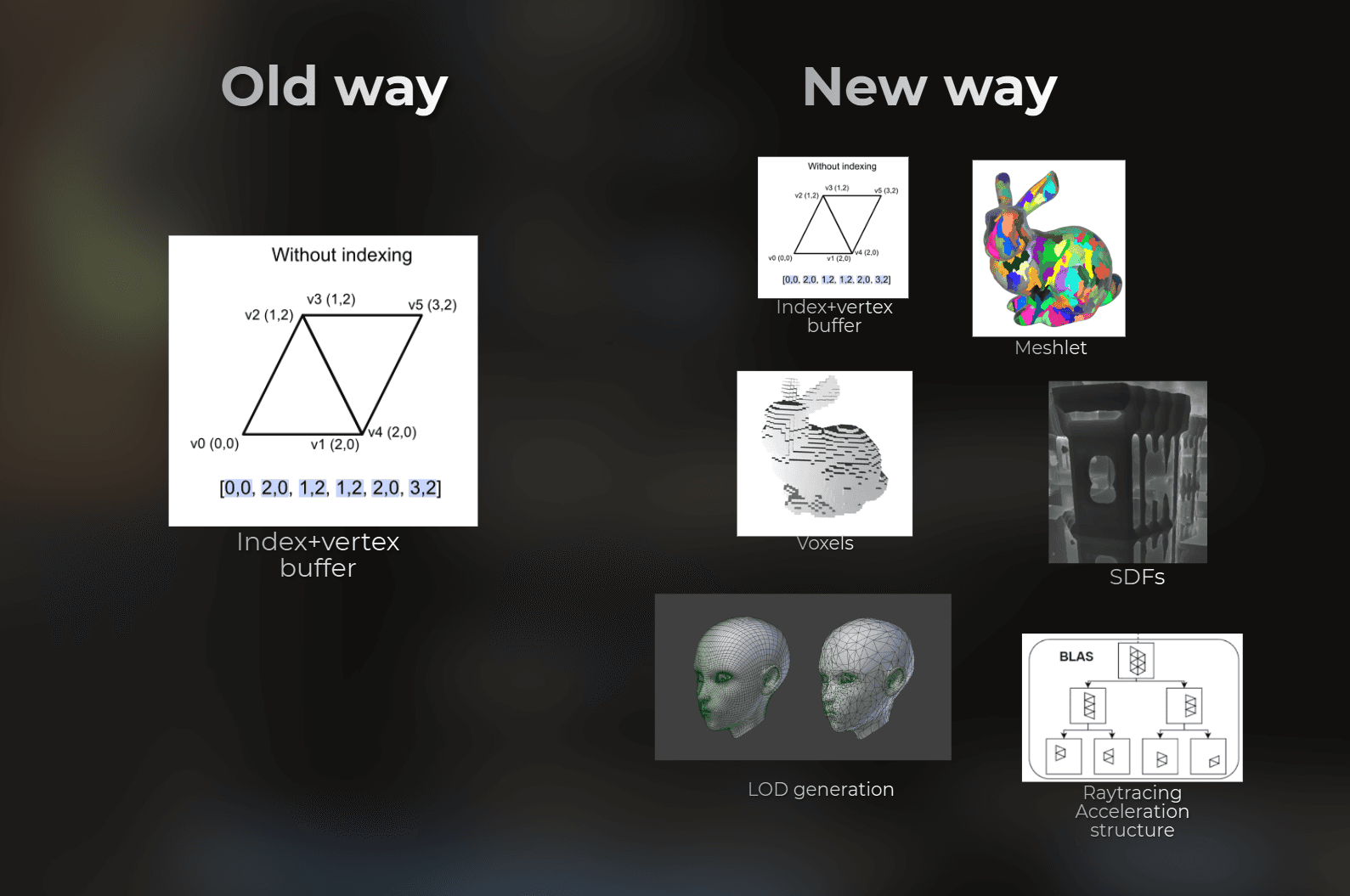
Importing an asset is genuinely complex now. And we will probably add neural compression and MLP-trained data decoders on top soon.
Engines also keep adding a lot of small features that all need to work together: shadow maps, prepasses, visibility buffers, geometry passes, VFX compute, upscaling, transparency, probe updates, GI compute, TAA, water simulation, postprocesses, frame generation...
I can't imagine how hard it is to keep such a complex tech stack that is well integrated together. Well I still wait to see the "well integrated together" part happening.
___
Implications of such a complex tech stack

Source: https://www.reddit.com/r/Unity3D/comments/n44shs/unity_then_vs_unity_now/
The complexity of this tech stack is so big that we often run into constraints like this:
You used nanite? Good luck with animating your vertices
Used this GI method? There is no support for emissive materials
Enabled hardware ray-traced reflections? No reflections on transparent objects
You know Shader Graph? Good luck with using that for custom render passes
You toggled this feature on a single mesh? Now we add 1ms of rendering to each frame to handle a different mesh format.
It is even hard to pick the right tech for your game in a single engine!
My hot take:
Because of that I think that engines adjusted for a very specific genre of a game will develop much better visuals than generic multi-purpose engines that need to maintain all of that.
___
Summary
Real-time raytracing works because we stack so much on top of the raw ray count: ray reuse, prediction, spatial and screen-space caching, denoising, upscaling. Strip that away and even today's GPUs still cannot give you "real" raytracing.
The future looks like more fragmentation, not one unified pipeline. PC+console, and mobile will keep diverging. Hybrid RT will live alongside classic rasterization for the next years.
Neural methods can have a big impact, but will require a different infrastructure for asset authoring - how we import textures, train small networks, and debug visual bugs that come from a bad loss function instead of a bad HLSL line.
If I had to pick one skill for the next five years, it would still be profilers and performance management on mid-range hardware.
Main takeaways:
Raytracing is possible due to advanced tech stack of ray reuse, prediction, caching, virtualization, denoising and upscailing, not only the hardware.
Understanding the full tech stack has probably never been this hard.
First time we didn't abandon the previous graphics APIs.
And starting to experiment with graphics was never easier.
The hardware split between mobile and PC got wider.
Neural rendering can be a next "big" thing.
The people who understand what is actually happening inside the GPU are more valuable than ever.

